The Silent Attack: Why Adversarial Vulnerabilities Are the Next Great Challenge for Autonomous AI
The recent headline—that a simple printed sign can be used to deliberately confuse a self-driving car into steering toward pedestrians or cause a drone to land in an unsafe area—is more than just a sensational piece of tech news. It serves as a crucial alarm bell ringing across the entire technology sector. This is not a simple software glitch; it is a clear demonstration of a sophisticated vulnerability inherent in the way modern Artificial Intelligence perceives the world: Adversarial Attacks.
For years, the AI community has celebrated the incredible leaps in accuracy achieved by deep learning models. Whether recognizing faces, understanding spoken commands, or navigating complex traffic patterns, these systems perform tasks that were once science fiction. However, this recent study reveals a hidden flaw: AI models are often brittle. They rely on patterns that are not always robust to deliberate, clever manipulation.
To truly understand what this means for the future of AI, we must look past the immediate danger and examine the underlying science, the industry’s response, and the regulatory shifts required to secure our increasingly automated world.
What is an Adversarial Attack? Understanding the Mathematical Blind Spot
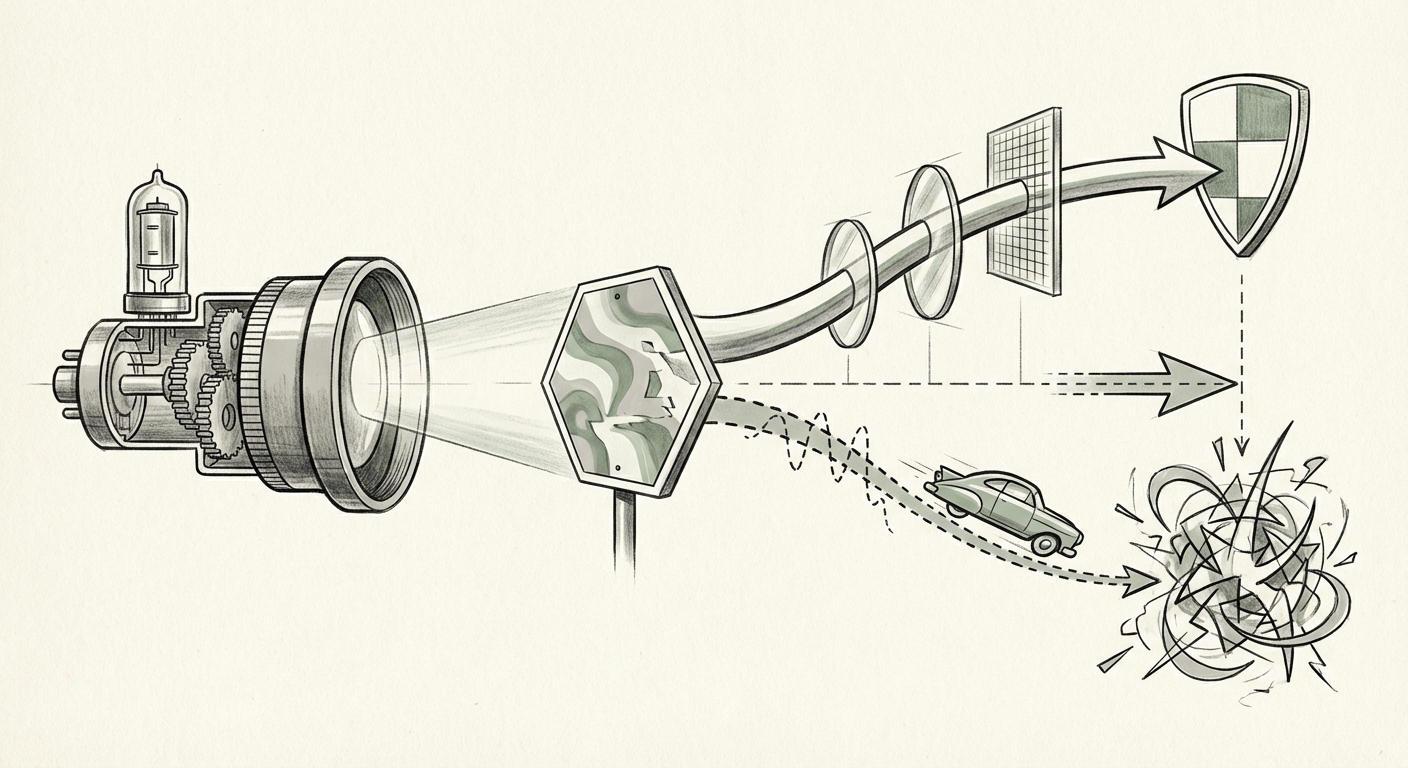
Imagine you are looking at a stop sign. You see a red octagon, and your brain instantly knows its meaning. An autonomous vehicle’s camera sees the sign, and its deep learning vision system analyzes the pixels to confirm: "Stop Sign."
An adversarial attack works by adding tiny, often invisible "noise" to that image—a carefully calculated pattern of pixels that the human eye cannot detect. To the human, the sign still looks perfectly normal. To the AI, however, that slight alteration makes the image suddenly read as something else entirely—perhaps a "Yield Sign" or even a "Speed Limit 45" sign. The system misclassifies the object with very high confidence, leading to catastrophic real-world actions.
This vulnerability isn't unique to cars. As research shows, these attacks can target any system reliant on deep learning perception:
- Physical Patches: As seen in the AV study, these attacks can be printed onto physical objects, making them effective in the real world, not just in a lab setting.
- Audio Attacks: Inaudible sounds can trick voice assistants into executing commands. (This connects to the general threat landscape across speech recognition systems.)
- Textual Attacks: Even Large Language Models (LLMs) can be manipulated through subtle changes in prompts to generate harmful or biased output.
Fundamentally, these models learn correlations rather than true understanding. Adversarial examples expose the difference between "seeing" and "understanding."
Corroboration: The Threat is Systemic, Not Isolated
The danger of the AV story is amplified when we see it reflected across other AI domains. The security challenge is unified across perception, language, and audio models. Examining the broader context confirms that the time for passive defense is over.
1. The Foundational Science of Fragility
The existence of these attacks is rooted in decades of research into "Adversarial Examples." This field validates that the mathematical structure of deep neural networks makes them susceptible to these specific, calculated inputs. When researchers pursue foundational work in this area, they are essentially mapping the weaknesses of the very technology we are beginning to rely on for critical infrastructure.
The implication for researchers is clear: Model training must evolve from maximizing accuracy on clean data to maximizing robustness against noisy or malicious data.
2. The Necessary Regulatory Reckoning
If a driver causes an accident due to faulty brakes, regulations and standards apply. When an algorithm causes an accident due to a programmed blind spot, the regulatory landscape must adapt swiftly. Agencies like the National Highway Traffic Safety Administration (NHTSA) are now forced to consider how to audit systems that are mathematically exploitable. Future certification for AVs won't just demand they drive safely; they will demand they survive sophisticated, targeted attacks.
For the auto industry, this means security is no longer an optional add-on; it becomes a primary hurdle for market entry and public trust.
3. Expanding Security Beyond the Camera Lens
The connection between visually manipulating a car and audibly manipulating a smart speaker highlights that security needs to be holistic. If your smart home assistant can be tricked by a subtle noise embedded in music to unlock your door, the trust erosion extends far beyond the road. This security gap is common across the entire ecosystem of deployed AI tools.
Businesses deploying any customer-facing or critical AI must adopt a unified security posture, recognizing that visual, audio, and text inputs all represent potential attack vectors.
Implications for the Future: Building Verified Resilience
What does this mean for how AI technology will be developed, sold, and governed over the next decade? The age of rapid, unverified deployment is drawing to a close. The future hinges on trust through verification.
For Business: Security as a Competitive Advantage
Companies focused on selling autonomous solutions must pivot their R&D budgets toward defensive measures. The market will soon distinguish between systems that merely perform well and systems that perform reliably under duress. The defensive strategies falling under the umbrella of "model hardening" will become paramount:
- Adversarial Training: Models are intentionally trained not only on normal data but also on examples that have been slightly corrupted by adversarial noise. This teaches the model what the noise looks like, allowing it to ignore it.
- Input Sanitization: Implementing pre-processing layers that detect and neutralize small perturbations before the data ever reaches the core recognition network.
- Certified Robustness: A growing trend where researchers aim to mathematically *prove* that a model will not misclassify an object within a certain boundary of input change. This moves defense from hoping for the best to guaranteeing a minimum level of safety.
Companies that can offer certified, demonstrable resilience against these attacks will command a premium and secure critical contracts in government and sensitive infrastructure sectors.
For Society: Rebuilding Trust in Autonomy
Public adoption of AVs, advanced robotics, and AI-driven decision-making stalls when high-profile failures occur. The ability for a simple piece of paper to cause chaos erodes the fundamental public trust required for these systems to integrate fully into society. We must ensure that the AI that manages our lives is significantly harder to fool than a human teenager pulling a prank.
This means transparency in testing. Regulators and the public will demand visibility into the adversarial stress-testing logs of any system operating in public domains. If a company cannot show how its system survived thousands of engineered "stop sign confusion" scenarios, its deployment timeline should rightfully be paused.
Actionable Insights: Where to Focus Now
- Audit Your Perception Stacks: If your organization uses computer vision or sensor fusion, immediately commission third-party audits specifically looking for susceptibility to known adversarial patch types.
- Integrate Security from Day One (Shift Left): Defense against these attacks cannot be patched on later. Robustness testing must be integrated into the Continuous Integration/Continuous Deployment (CI/CD) pipeline for all models entering production.
- Diversify Sensor Inputs: Over-reliance on a single sensor modality (like cameras) creates a single point of failure. Future robust systems will use sensor fusion (combining LiDAR, Radar, and Cameras) in ways that make coordinated, multi-sensor adversarial attacks exponentially more difficult.
The incident involving the manipulated sign is not just a threat; it’s a valuable data point. It confirms that the primary barrier to achieving mass adoption of truly autonomous systems is not overcoming physical complexity, but conquering mathematical fragility. The next generation of AI leadership will belong to those who prioritize verifiable defense over mere dazzling performance.
Conclusion for the Blog Post
The hijacking study serves as a crucial inflection point. It validates the theoretical concept of adversarial attacks in a high-stakes, real-world scenario. The future of autonomous technology—whether in cars, logistics drones, or advanced robotics—will not be defined solely by achieving higher accuracy, but by demonstrating verified resilience. The market will increasingly favor systems that have successfully incorporated robust, scientifically sound defenses against these cleverly engineered blind spots.