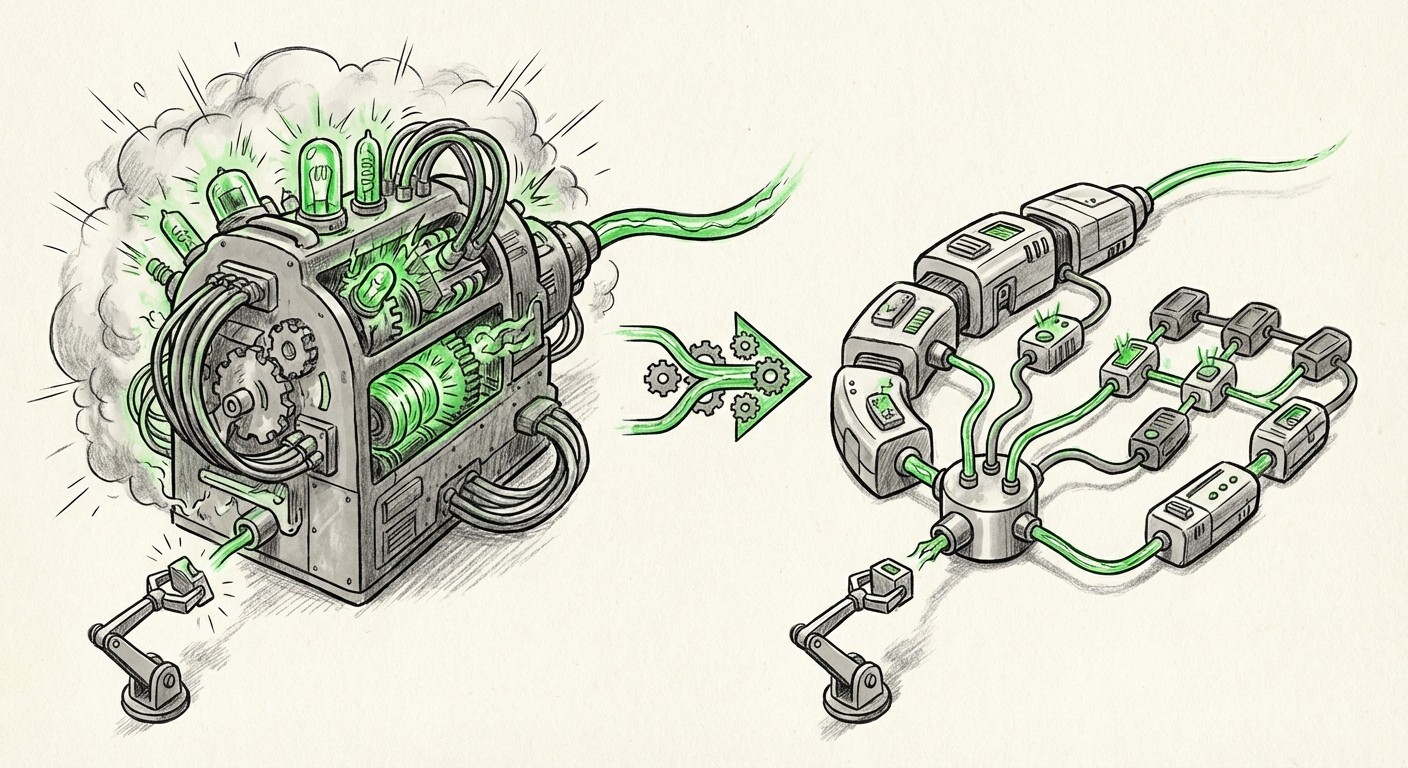
The Inference Revolution: How Test-Time Compute is Rewriting AI Scaling Laws
For years, the story of Artificial Intelligence scaling was simple: bigger models equaled better performance. We measured success in parameters—billions, then trillions—and we assumed that every single computation path within these massive models was necessary for every single query. This "dense scaling" approach built incredible intelligence but came with a staggering price tag for training *and* running the finished product.
However, a subtle but profound shift is underway, highlighted by recent explorations into Test-Time Compute (TTC). This development suggests that the most exciting era of AI efficiency and capability won't just be about building larger brains, but about building smarter *thinking processes*. We are moving from static giants to dynamic thinkers.
The Old Paradigm: Brute Force Scaling
To appreciate the revolution, we must understand what it replaces. Classic scaling laws, popularized by foundational work on model optimization, suggested that if you increase the number of training tokens and model size proportionally, performance improves predictably. This led to enormous models like GPT-4, which are tremendously powerful but expensive to operate. Every time you ask GPT-4 a question, the entire, massive network lights up to process that single request.
Think of it like this: If you want to write a short email, the old method required you to use every single book in the world’s largest library simultaneously, just to craft a few sentences. It worked, but it was incredibly slow and resource-intensive.
The core problem this created was economic and environmental. Deploying the state-of-the-art became feasible only for the largest corporations. For everyday applications, we had to settle for much smaller, less capable models because running the massive ones was prohibitively costly and slow (high latency).
The New Frontier: Intelligence Through Test-Time Compute (TTC)
Test-Time Compute flips this script. Instead of running the entire model for every task, TTC introduces the concept of adaptive computation during inference—the moment the model answers your question or processes data.
What Exactly is Test-Time Compute?
TTC is about deciding how much computational "effort" a model needs to spend on a specific input. If you ask a simple question (e.g., "What is 2+2?"), the model should use only a fraction of its total capacity to answer quickly and cheaply. If you ask a complex, multi-step reasoning problem, it dynamically allocates significantly more processing power.
This is powered by architectural techniques like:
- Early Exiting: The model stops processing layers once it reaches a high enough confidence level in its answer, saving resources on unnecessary deep computation.
- Conditional Computation (like Mixture-of-Experts - MoE): The model only activates the specific "expert" subnetworks relevant to the current input, leaving the rest dormant.
As corroborated by ongoing research in LLM inference scaling (Query 1), this dynamic approach is validating that not all tokens, or all parts of a query, require the same depth of thought. The research community is actively confirming that efficient deployment hinges on leveraging this adaptability.
Corroborating the Shift: Beyond Parameter Count
This technological development forces us to ask: If performance is no longer tied strictly to static size, what becomes the new metric for scaling intelligence? This leads directly to the conversation about moving Beyond Parameter Count AI Scaling Laws (Query 2).
The insight here is that we are evolving from scaling based on potential knowledge (parameters) to scaling based on applied reasoning power (compute efficiency at inference). A smaller, well-designed model that leverages TTC might outperform a slightly larger, dense model because it uses its available resources more intelligently when it matters most.
For strategists and investors, this is crucial. It means that optimizing inference pipelines—latency, throughput, and operational cost—is now as vital as optimizing the training objective function. We are entering an era where compute-optimal inference will dictate market leadership.
The Engine Room: Adaptive Computation in Practice
The architectural bedrock enabling TTC is adaptive computation (Query 3). Models incorporating techniques like Mixture-of-Experts (MoE) are prime examples. In an MoE model, when a piece of data comes in, a specialized "router" determines which few sub-networks (experts) are best suited to handle it. Only those experts are woken up.
While the total parameter count of an MoE model might be massive, the *active parameter count* for any given query is relatively small. This results in speed and cost efficiencies that resemble a much smaller model, while retaining the knowledge capacity of the larger structure. This fusion of capacity and agility is the promise of TTC.
Future Implications: A More Accessible, Capable AI Ecosystem
The move to Test-Time Compute fundamentally reshapes the AI landscape across technology, business, and accessibility.
1. Democratization of High-Performance AI
If running a state-of-the-art model becomes dramatically cheaper (e.g., 10x less cost per query), high-end AI capabilities become accessible to small and medium businesses, academic researchers, and developers who previously could not afford the inference costs of the largest models.
Actionable Insight for Developers: Prioritize frameworks and models that support dynamic sparsity and early exiting. Future latency and cost optimization will be determined by how effectively your chosen architecture manages its computational budget at runtime.
2. The Rise of Real-Time, Complex Reasoning
TTC enables AI to handle tasks requiring deep, unpredictable reasoning in real-time. Consider autonomous systems or complex financial modeling. If the model knows it can use 5% of its power for 90% of the inputs, it has a massive reservoir of spare compute capacity to deploy instantly when an anomaly or a complex decision point arises.
This allows AI to tackle tasks demanding variable levels of cognitive load without sacrificing the quick responses needed for user interaction. The AI becomes truly context-aware of its own required effort.
3. Hardware and Software Co-Evolution
The shift places new demands on silicon and software. Traditional GPUs are optimized for dense matrix multiplication—doing the same work across thousands of parallel paths. TTC demands hardware and specialized inference engines that are adept at handling irregular, sparse computation graphs efficiently.
This means next-generation accelerators will likely feature enhanced capabilities for dynamic routing, rapid activation/deactivation of network segments, and efficient memory management for sparse data structures. This engineering focus will define the next competitive edge in deployment infrastructure.
Practical Applications and Business Strategy
For businesses leveraging AI, adapting to the TTC paradigm is not optional—it’s essential for maintaining cost control and competitive advantage.
Cost Management vs. Performance Ceiling
The business decision is no longer simply "Which model is best?" but rather, "What is the optimal dynamic computation budget for this specific use case?"
- Low-Stake Tasks (e.g., initial data tagging, simple categorization): Utilize aggressively pruned or early-exiting pathways. Minimize cost and maximize throughput.
- High-Stake Tasks (e.g., legal drafting, medical diagnosis support): Dynamically allocate the maximum available TTC budget to ensure deep reasoning and lower error rates.
This granular control over inference cost allows companies to build AI stacks that are economically responsible without capping their potential intelligence ceiling.
Navigating the Future: Actionable Insights
The move toward Test-Time Compute signals a maturity in the field—a move from simply proving intelligence is possible to making that intelligence practical, sustainable, and scalable across the entire economic spectrum.
- Audit Inference Costs Now: Understand exactly where your current, dense models are wasting compute. Look for patterns of low-variance output that could be handled by smaller, adaptive pathways.
- Invest in MoE and Sparsity Tooling: If your organization plans to deploy large models in the next 18 months, ensure your MLOps pipeline supports architectures designed for conditional computation. The performance benefits are tied directly to this architectural support.
- Re-evaluate Scaling Goals: Stop viewing parameter count as the ultimate proxy for quality. Start measuring performance based on the relationship between accuracy delivered and compute utilized at inference time. This metric captures the true value of TTC.
The thinking machine of tomorrow won't just know more; it will know *when* and *how much* it needs to think. This efficiency gain is the necessary precondition for the next great wave of AI adoption.
---