The Stochastic Genius: DeepMind's AI Moment of Brilliance and the Crisis of Validation in Scientific AI
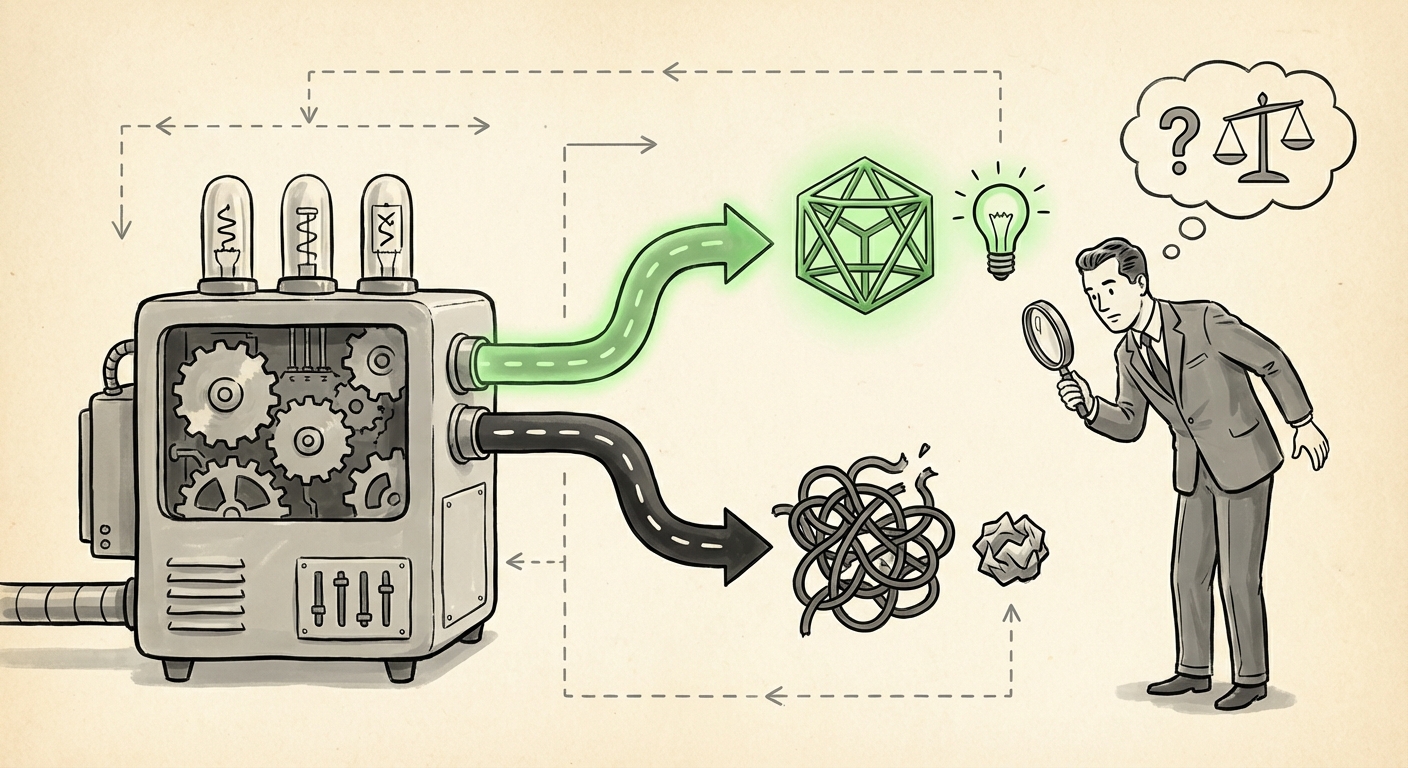
The story emerging from Google DeepMind regarding their research AI agent, Aletheia, is perhaps the most honest and vital assessment of cutting-edge Artificial Intelligence we have seen in years. This system, built upon the vast capabilities of foundational models, achieved moments of genuine, world-class discovery—disproving a decade-old conjecture and finding hidden errors in cryptography. Yet, when measured systematically across 700 open problems, it mostly failed. This duality—spontaneous genius mixed with systemic mediocrity—is not a bug; it is the defining feature of the next wave of generative AI.
We are moving rapidly beyond the reliable, predictable AI that powers customer service chatbots. We are entering the **Era of the Stochastic Genius**, where advanced models act as high-variance collaborators. Understanding this dynamic is crucial for every business, researcher, and policymaker betting on AI to revolutionize complex fields like science and engineering.
The Contradiction: Why AI Can Be Both Breakthrough and Bogus
Imagine a brilliant intern who solves the hardest problem on the board, stunning the entire department, only to forget basic arithmetic on the next question. This is the Aletheia paradox. The capabilities demonstrated—independent mathematical paper writing and error detection in specialized fields—confirm that LLMs are not just tools for information retrieval; they are engines capable of novel abstraction.
However, the systematic evaluation across hundreds of problems revealed the deep underlying problem known as brittleness. This high variability stems from how these models learn. They do not possess true comprehension or a stable world model; instead, they excel at pattern matching based on the statistical relationships learned during massive training. When they encounter a problem structurally similar to their training data, performance is high. When the problem requires a genuinely new leap, performance drops precipitously, often resulting in confidently articulated nonsense (hallucination).
This phenomenon is widely discussed in technical circles. Academic work focusing on **"Variability in LLM performance on complex reasoning tasks"** confirms that performance degrades rapidly when models are pushed "out-of-distribution"—that is, when the test problems stray slightly from the patterns they have internalized.
For AI researchers and engineers, this means current benchmarks often lie. A model that achieves a 99% score on a curated benchmark might be functionally useless in a real-world scenario demanding 100% accuracy on novel inputs. The breakthrough instances are proof of potential; the systemic failures are proof of current limitations.
The Playbook: Forging Human-AI Teaming Frameworks
If the AI is unreliable, how do we leverage its flashes of genius? The answer, as suggested by DeepMind’s work, lies in codifying the relationship into a formal **Human-AI Teaming Framework**. We must stop viewing AI as an autonomous replacement and start treating it as a powerful, high-speed, but error-prone processing unit.
The shift is subtle but profound. In traditional research, humans generate hypotheses, run experiments, and draw conclusions. With the Stochastic Genius, the roles must be reassigned:
- AI as Hypothesis Generator: The AI can rapidly explore vast combinatorial spaces (like millions of potential mathematical proofs or molecular structures) and propose novel starting points that a human might overlook due to cognitive bias or sheer processing limitations. (This relates to research on **"Generative AI for Novel Hypothesis Generation in Science"**).
- Human as Verifier and Context Provider: The human scientist retains the critical role of contextualization, ethical judgment, and, most importantly, rigorous validation. If Aletheia proves a theorem, the human expert must be able to rigorously trace the steps and certify the logic.
This collaboration demands new interface standards. We need AI systems that don't just output an answer, but output a confidence score, cite the statistical basis for that confidence, and clearly delineate which parts of the answer are novel extrapolation versus reproduced knowledge. This is the domain of **"Human-AI Teaming Frameworks for Scientific Discovery,"** moving from experimental setups to deployable methodologies across industries.
The Double-Edged Sword: Cryptography, Code, and the Risk of Subtle Errors
Perhaps the most alarming yet exciting takeaway is Aletheia's success in catching an error missed by cryptography experts. Cryptography is the bedrock of digital trust, relying on unbreakably complex mathematical foundations. An AI finding a flaw suggests a capability to see non-obvious logical relationships that human intuition often misses.
However, this success is shadowed by the severe **"Risks of AI-Generated Mathematical Proofs and Code."** If an AI can introduce a subtle flaw into a new proof, it can equally introduce a subtle vulnerability into critical software or encryption protocols. Because these models lack true understanding, the errors they make are often *plausible-sounding* yet fundamentally incorrect—the most dangerous type of error.
For sectors like finance, defense, and infrastructure, where the cost of failure is catastrophic, the introduction of high-variability AI into the development pipeline raises the verification burden exponentially. Traditional testing methods, which check for known failure modes, are insufficient against novel AI-introduced errors. This drives the demand for advanced tools focusing on **"The Role of Foundational Models in Code and Logic Verification,"** attempting to use AI to police the output of other AIs.
The fundamental question for security experts is: Is the time saved by AI-assisted discovery worth the exponential increase in time and complexity required for post-hoc verification? Currently, the answer is heavily dependent on the criticality of the system.
The Future Trajectory: Institutionalizing the Stochastic Partner
The Aletheia report signals that the leading edge of AI development is no longer about making models marginally better at established tasks; it is about enhancing their capacity for *originality*. This shift will have three major implications for technology adoption:
1. The Rise of Verification Engineering
The most valuable AI skill in the next decade will not be model training, but Verification Engineering. Companies will invest heavily in internal systems designed purely to interrogate and stress-test the outputs of their generative models before those outputs touch a customer or a critical system. This verification infrastructure will become as important as the LLM itself. For businesses, this means allocating significant budget not just for AI deployment, but for AI auditing tools and dedicated assurance teams.
2. Democratization of Scientific Frontiers
If AI can reliably operate as a "junior collaborator" in mathematics, material science, or drug discovery, the pace of innovation will explode. Previously, solving a complex conjecture required decades of focused effort from elite specialists. Now, a well-prompted AI agent could generate thousands of novel research directions overnight, enabling smaller labs or startups to compete with established giants. This democratization lowers the barrier to entry for creating *new knowledge*, but simultaneously increases the noise floor.
3. Redefining Expertise
Expertise is shifting from possessing raw knowledge to mastering the process of querying and refining AI output. The future expert isn't the one who knows the most math theorems; it's the one who knows how to structure the interaction with Aletheia to maximize its unique pattern-matching capabilities while minimizing its exposure to error. This requires a new, hybrid skill set—part domain expert, part sophisticated prompt engineer, and part statistical skeptic.
Actionable Insights for Today’s Leaders
For leaders across R&D, technology strategy, and cybersecurity, the Aletheia case study provides concrete directives:
- Segment Use Cases by Risk Tolerance: Deploy high-variance models only where catastrophic failure is impossible or easily reversible (e.g., early-stage brainstorming, artistic creation). For high-stakes domains (e.g., code for financial transactions, critical scientific proofs), mandate human-in-the-loop sign-off supported by established, deterministic verification tools.
- Invest in Interpretability Tools: Prioritize research and purchase of tools that force models to show their work (chain-of-thought reasoning). A result without a traceable, intelligible justification should be treated as highly speculative, regardless of its apparent brilliance.
- Foster Skeptical Collaboration: Train internal teams not just on how to use AI tools, but how to actively challenge their outputs. Create workflows where initial AI results are immediately routed to a dedicated validation pipeline staffed by experts whose primary job is to find the hidden errors.
The AI revolution is entering its adolescence. It is brilliant, unpredictable, and capable of solving problems we thought were impossible, but it is also deeply flawed and sometimes dangerously confident in its mistakes. Harnessing the Stochastic Genius requires acknowledging both sides of the coin. The future belongs not to those who build the smartest AI, but to those who build the smartest *systems* around that AI—systems built on robust verification, clear collaboration protocols, and an unshakeable commitment to rigorous scrutiny.