Why More Context in AI Coding Agents Actually Makes Them Worse: The Relevance Revolution
For years, the mantra in scaling Artificial Intelligence—especially for complex tasks like software development—has been simple: More data equals better results. We assumed that giving a coding agent access to an entire codebase, a mountain of documentation, and ten related libraries would lead to flawless, context-aware suggestions. However, recent, sobering research regarding AI coding assistants suggests this assumption is fundamentally flawed. A recent finding shows that feeding these agents large numbers of "context files" often doesn't just fail to help; it actively degrades their performance.
This is not a minor bug; it is a pivotal inflection point in AI deployment. It forces us to abandon the brute-force approach of "context volume" and pivot sharply toward the science of **context quality and relevance**. For engineers, product managers, and business leaders betting on AI productivity tools, understanding this shift is crucial for determining where investment in AI infrastructure truly pays off.
The Surprising Failure of Context Overload
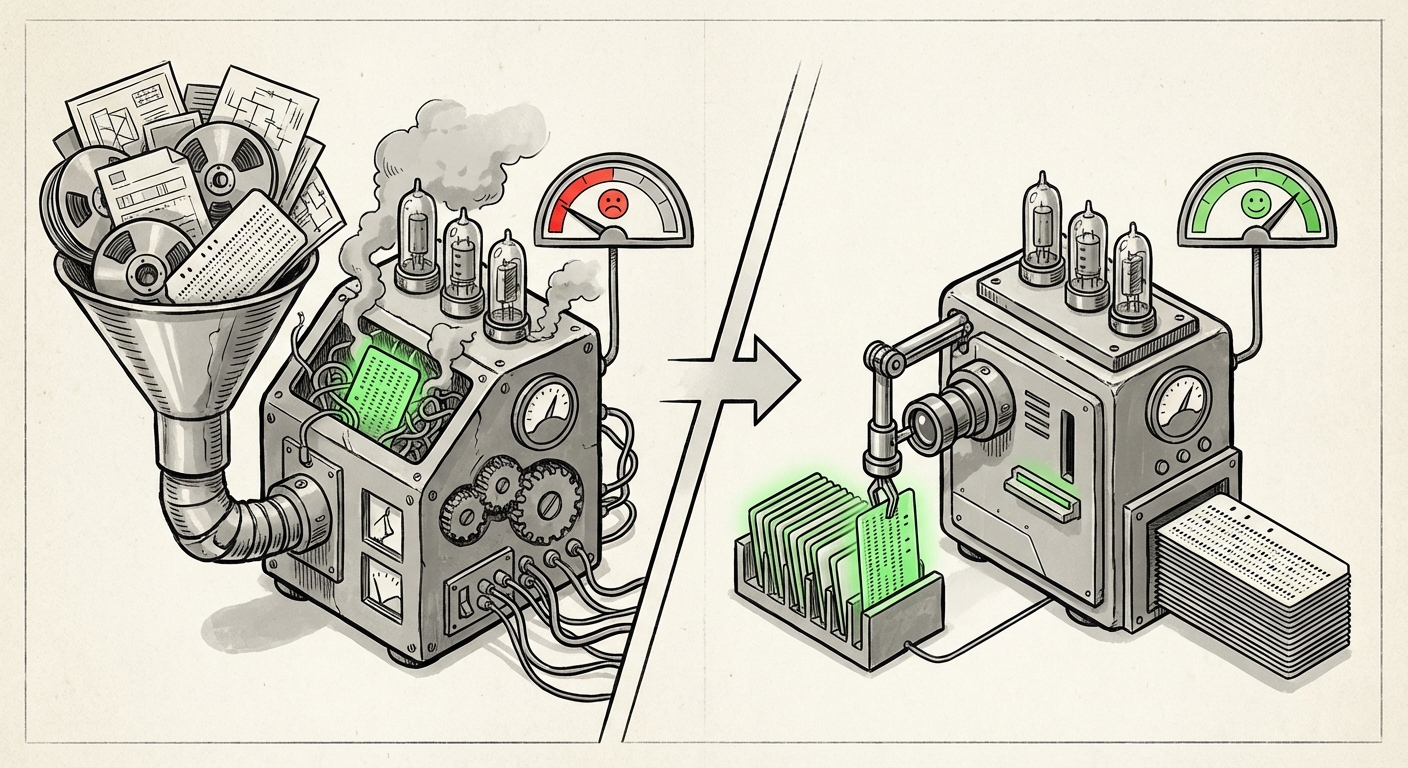
Imagine you are a junior programmer asked to fix a bug in one specific function. Your manager hands you a stack of 50 manuals, 20 different project histories, and three unrelated design documents, saying, "The answer is in there somewhere." You would likely spend hours drowning in irrelevant noise before finding the single necessary paragraph. Modern LLMs, the engines powering these AI coding agents, face the exact same challenge when their context window—their temporary working memory—is stuffed with dozens of files.
The research points to a clear conclusion: simply shoving context files into the prompt acts as noise pollution. The model either becomes confused, misinterprets the core task due to conflicting information, or fails to prioritize the small, vital piece of code it actually needs to reference.
The Scientific Basis: Lost in the Middle
To understand why this happens, we must look inside the "brain" of the LLM. Researchers have documented a phenomenon known as the "Lost in the Middle" effect. This effect demonstrates that LLMs do not read context linearly or perfectly weight all information equally.
- Focus on Extremes: Models tend to pay strong attention to information placed right at the very beginning of the prompt and information placed right at the very end.
- The Forgotten Center: Crucial facts buried deep in the middle of a long document or a long list of context files are frequently ignored or undervalued by the model when it generates its final output.
If a developer asks the AI to modify file A, but the critical dependency definition is buried as the 15th context file provided, the model might generate broken code simply because it never truly registered that dependency. This mechanism explains the performance degradation: the added context isn't ignored; it actively crowds out the useful signal with irrelevant distraction.
The RAG Framework: Where Context Management Meets Reality
The concept of feeding an LLM external, specific information is formally managed through systems called Retrieval-Augmented Generation (RAG). While the context files provided manually to a coding agent might seem simpler than a full RAG pipeline, they operate under the same constraints. RAG is the industry standard for grounding generalized models in proprietary data—whether it’s internal HR manuals or proprietary source code.
The failure of simple context injection highlights the complexity of building effective RAG:
- The Embedding Problem: RAG systems first turn all documents into numerical representations (embeddings) for searching. If the search mechanism (the retrieval step) pulls ten files that are only 40% relevant, the model is immediately hampered.
- Chunking Matters: How you divide large files into searchable "chunks" critically impacts retrieval. Poor chunking means the right information is never isolated for the model.
- Failure Modes: Industry analysis of RAG systems reveals common failure modes related to context overload. When systems fail, it’s usually because the retrieval step was too broad, leading to the exact noise pollution observed in the coding agent studies. Systems that perform well utilize advanced techniques like re-ranking (checking the retrieved results again) or multi-hop retrieval (asking the model to search again based on initial findings) to combat this noise.
For an AI coding agent, the codebase is the RAG corpus. If the retrieval step simply grabs the five most recently modified files instead of the file defining the specific class being called, the result will be poor, regardless of the model's underlying intelligence.
Industry in Practice: Grounding Agents in Massive Codebases
The theoretical limits of LLMs are tested every day in companies wrestling with integrating AI assistants into massive, complex software ecosystems. These environments are far more intricate than simple homework problems; they involve thousands of dependencies, outdated libraries, and unique architectural patterns.
The search for successful context management reveals a pattern of increasing sophistication beyond simple file inclusion. Companies deploying tools like GitHub Copilot or internal, proprietary code agents are focusing intensely on grounding—ensuring the model’s output is factually correct based on the existing, specific codebase.
- Dependency Mapping: The most effective systems don't just look at the file being edited; they dynamically map out the dependency graph for that file. If you modify a utility class, the agent must know to pull the definition of that utility class, even if it's three directories away, rather than pulling unrelated files from the same directory.
- Historical Context: Advanced agents are starting to incorporate historical context—not just code, but surrounding metadata like previous pull request comments or bug reports related to the file, which helps clarify the *intent* behind the current code structure.
The practical implication here is that the value proposition of AI coding tools is shifting. It’s not about the model’s raw reasoning power; it’s about the **pre-processing pipeline** that serves the context. A company with a well-organized, well-indexed codebase will see exponentially better results from its AI tools than a company with a messy, undocumented repository, even if both use the exact same large language model.
Future Implications: What This Means for AI Deployment
This research signals a fundamental change in how we will build and use AI assistants across all domains, not just coding. The next era of AI success will be defined by engineering discipline around context delivery.
1. The Rise of Context Engineering
We are witnessing the formalization of "Context Engineering." This discipline focuses purely on optimizing the input to maximize the signal-to-noise ratio for the LLM. This involves:
- Adaptive Retrieval: Building systems that can iterate—searching, analyzing the first batch of results, discarding the weak ones, and searching again with refined queries.
- Context Condensation: Using smaller, faster LLMs specifically trained to summarize or distill large retrieved documents into 1-2 sentences of highly potent, actionable context before feeding it to the main reasoning model.
2. Business Value is Tied to Data Hygiene
For businesses, the lesson is clear: investing in clean, well-structured internal data—whether code, financial reports, or customer service logs—is no longer optional housekeeping; it is a prerequisite for effective generative AI adoption. If your data is a jungle, the AI will get lost in it. The ROI of an AI assistant is directly proportional to the quality of the search layer powering its context.
3. The Evolution of the Context Window
While hardware advancements continue to push context windows larger (e.g., 1 million tokens), these massive windows will likely remain general-purpose buffers, not primary working memory for task execution. For focused tasks, the trend will be to use a smaller, surgically precise context derived from a sophisticated retrieval system. Why pay the computational cost and suffer the performance drop of a million tokens when 2,000 perfectly relevant tokens suffice?
Actionable Insights for Developers and Leaders
How can technology teams adapt to this new reality where context volume is a liability?
For Technical Teams (Engineers & Architects):
- Audit Your Retrieval Strategy: If you are using RAG for any internal application, stop relying on simple vector similarity alone. Implement **re-ranking models** or hybrid search techniques (combining keyword and vector search) to ensure retrieved chunks are contextually dense.
- Test for "Lost in the Middle": When benchmarking AI performance, deliberately place critical data points in the middle of large context loads. If performance drops significantly compared to when the data is at the start or end, you have a retrieval problem, not a model problem.
- Focus on Metadata: Improve your data indexing by attaching rich metadata (e.g., function signature, last updated date, author comments) to your data chunks. This allows the retrieval system to filter based on *meaning* and *recency*, not just semantic similarity.
For Business Leaders (CTOs & VPs):
- Demand Context Transparency: When adopting third-party AI tools, ask vendors precisely *how* they select context for complex tasks. If they cannot articulate a sophisticated filtering or retrieval layer, assume you are paying for noise.
- Prioritize Data Governance for AI: Recognize that internal data cleanliness directly translates to AI performance and security. Poorly documented, scattered codebases will yield AI tools that introduce bugs, not efficiency gains.
- Invest in Orchestration Layers: The future value is in the orchestration layer—the code that manages *when*, *what*, and *how* context is passed to the LLM. This layer is where your competitive advantage in specialized AI applications will be built.
The path forward for AI assistants is not about brute-forcing memory; it is about achieving surgical precision. The era of simply throwing more data at the wall to see what sticks is over. The next major advancements in AI productivity will emerge not from bigger models, but from smarter, more disciplined information delivery systems.