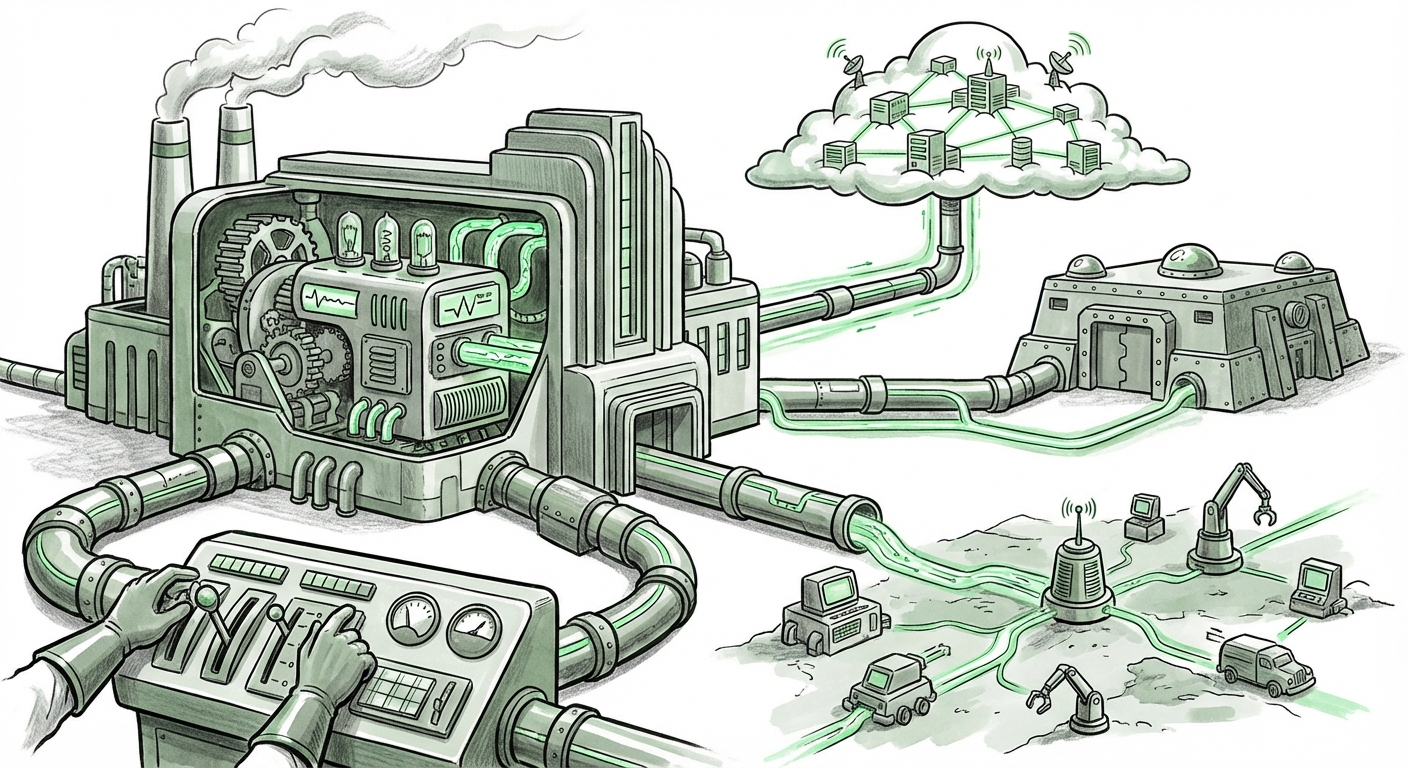
The Unified AI Factory: Deconstructing Hybrid Deployment for AMD MI355X and LLMs
The landscape of Artificial Intelligence deployment is undergoing a profound transformation. No longer is AI confined to massive, centralized cloud data centers. The future is distributed, flexible, and acutely sensitive to resource efficiency. A recent guide detailing the deployment of what appears to be a specialized AI platform (dubbed "MCP") leveraging hardware like the **AMD MI355X** across Software-as-a-Service (SaaS), Virtual Private Cloud (VPC), and On-Premises environments crystallizes this shift.
As an AI technology analyst, this signals more than just vendor flexibility; it signals a fundamental change in *how* enterprises access, control, and scale their most valuable digital assets—their AI models. This article synthesizes the implications of this hybrid deployment reality, anchored by specific hardware innovations and the relentless demands of modern Large Language Models (LLMs).
The Great Infrastructure Split: Why Hybrid is the New Standard
For years, the default strategy was "lift-and-shift" to the public cloud. While excellent for experimentation, this model breaks down when dealing with production-grade, high-throughput AI. Why? Three primary factors:
- Data Sovereignty and Security: Highly regulated industries (finance, healthcare) cannot always afford to have sensitive training data or proprietary inference traffic leave their own secure walls (On-Prem).
- Latency: Real-time applications, like autonomous systems or low-latency trading, demand processing speed that even the fastest public cloud connection cannot guarantee. The processing must be close to the action—the "Edge" or the private data center (VPC).
- Cost Predictability: Training and serving massive LLMs involves sustained, immense compute power. Predictable operational expenditure (OpEx) often favors owning the hardware (On-Prem/VPC) for the long term, rather than paying ever-increasing cloud egress and compute fees.
The concept of deploying a unified platform across SaaS, VPC, and On-Prem is the architectural response to these pressures. It aims to deliver the control of owning your hardware with the agility of the cloud. This is the "Unified AI Factory" concept.
Corroborating the Hardware: The Role of the MI355X
The reference to the **AMD MI355X** is highly significant. In the high-stakes race for AI dominance, hardware specifications dictate strategy. For enterprise deployments focused on serious LLM work, two metrics matter most: sheer processing power (teraFLOPS) and, crucially, high-bandwidth memory (HBM).
We must look beyond marketing and seek concrete validation. If we search for `"AMD MI355X" performance benchmarks LLM inference`, we are looking for independent proof that this chip can compete effectively in the high-end training and serving market dominated by Nvidia. The performance of the MI355X—specifically its memory subsystem and scaling capabilities—is the technical linchpin supporting the hybrid deployment narrative. If the hardware is powerful enough, enterprises feel comfortable installing it in their own data centers (On-Prem/VPC), knowing they are not settling for second-best.
This trend validates the broader industry move toward hardware diversification. Enterprises are increasingly adopting multi-vendor strategies to mitigate supply chain risks and optimize cost curves, making platform providers capable of managing both Nvidia and AMD ecosystems highly valuable.
The Memory Wall: Why LLMs Define Infrastructure Decisions
The explosion in model size has created the "memory wall." Training a cutting-edge model or even just running inference on a large foundational model often requires more GPU memory (VRAM) than a single accelerator possesses. This forces a dependency on sophisticated distributed computing techniques.
Searching for context on `LLM inference memory requirements vs hardware capacity trends` reveals that memory capacity, not just raw compute speed, is the primary bottleneck today. Models like Llama 3 or specialized Mixture-of-Experts (MoE) architectures are memory-hungry. This directly impacts deployment choices:
- Training: Requires massive HBM pools across hundreds or thousands of interconnected chips, often centralized where high-speed, low-latency interconnects (like InfiniBand or proprietary solutions) are feasible.
- Inference: Even serving a popular model requires keeping the entire weight set in fast memory. If an organization wants to serve a 70-billion parameter model reliably across its private network, the underlying hardware must have massive on-board memory capacity, such as what next-generation accelerators like the potential MI355X promise.
Actionable Insight: For businesses, understanding memory requirements means choosing between techniques like quantization (shrinking the model's precision to fit into smaller memory footprints) or investing in hardware with higher HBM density. The hybrid deployment model allows organizations to place the most memory-intensive training jobs in specialized, centralized cloud or On-Prem clusters, while deploying smaller, optimized inference models across edge locations.
The MLOps Tightrope Walk: Unifying the Disparate Factory Floor
Having hardware located everywhere—in the cloud provider’s managed environment (SaaS), within your own dedicated cloud slice (VPC), and in your basement server room (On-Prem)—is a logistical nightmare without the right tooling. This is where Machine Learning Operations (MLOps) enters the frame.
If we examine the `Challenges of MLOps across hybrid cloud and on-premise environments`, the focus immediately shifts from hardware performance to process standardization. How do you ensure a model trained securely in the VPC can be deployed seamlessly to a SaaS partner for customer-facing analytics, all while tracking versioning, drift, and compliance?
This mandates abstraction layers. Platforms like Kubernetes, often extended by enterprise solutions (e.g., **Red Hat OpenShift AI**), become essential. They create a consistent operating environment—a control plane—that abstracts away the underlying physical differences between a cloud instance and an on-prem server.
Practical Implication: The success of the MCP model described in the initial article hinges entirely on the robustness of its MLOps layer. Without this abstraction, different environments require entirely different deployment scripts, leading to slow iteration, high error rates, and security gaps. For IT leaders, the investment in a unified MLOps platform that understands heterogeneous hardware topologies is no longer optional; it is foundational.
Future Implications: Sovereignty, Latency, and the Edge AI Revolution
The move toward hybrid deployment is not a temporary phase; it is the blueprint for the next decade of enterprise AI adoption. It directly addresses geopolitical and operational realities.
Data Sovereignty Demands On-Prem Investment
Reports tracking global IT spending continually highlight the growing influence of data residency laws. Searching for the `Future role of on-premise data centers in AI compute strategy` confirms that many critical, regulated workloads must remain within specific physical borders. This forces corporations to maintain high-capacity private clusters.
The unified MCP framework allows these entities to comply perfectly with regulations (by keeping sensitive data On-Prem) while leveraging the infinite scalability of the SaaS cloud for non-sensitive tasks like model experimentation or customer-facing web interfaces.
AI at the Speed of Life
Beyond data compliance, there is the physical limitation of speed. Future AI will be deeply embedded in physical operations—robotics, autonomous vehicles, smart factories. These use cases demand millisecond response times. Data travelling hundreds of miles to a central cloud server and back is simply too slow.
This necessitates AI moving closer to the point of data generation—the edge. While the MI355X might be too powerful for a tiny edge device, the hybrid architecture allows the enterprise to manage a large, powerful On-Prem hub that serves smaller, specialized inference engines at the actual edge location. The centralized platform manages the *master models*, and the edge runs the *local execution*.
Actionable Insights for Business and Technology Leaders
How do organizations successfully navigate this complex, distributed future?
- Audit Your Latency Needs: Categorize all AI workloads. Which absolutely require On-Prem/VPC due to latency (e.g., robotics, financial HFT)? Which can tolerate public cloud latency (e.g., batch processing, generic chatbots)? This informs hardware purchasing decisions for your private clusters.
- Invest in Abstraction, Not Specifics: When selecting orchestration tools, prioritize those that offer hardware-agnostic abstraction (i.e., those managing diverse AMD and Nvidia hardware under one roof). Focus on unified MLOps pipelines rather than optimizing for one specific GPU vendor in one specific cloud region.
- Embrace Specialized Silicon: The era of relying solely on one major chip supplier is ending. Actively evaluate emerging hardware competitors, like AMD’s offerings, based on their specific strengths (e.g., HBM capacity for LLMs) rather than legacy brand loyalty. This mitigates risk and drives down long-term costs.
- Develop Cross-Environmental Security Policies: A unified deployment requires unified security. Ensure your governance framework (how access is granted, how data is encrypted in transit and at rest) is identically applied whether the model is running on a SaaS partner’s server or your corporate rack.
The deployment of advanced AI solutions across SaaS, VPC, and On-Premises environments is not merely a technical convenience; it is an economic and regulatory necessity. Driven by powerful, specialized hardware like the AMD MI355X and constrained by the immense memory needs of LLMs, enterprises are building resilient, multi-faceted AI factories. The winners in the next wave of AI adoption will be those who master the operational complexity of this distribution.