The Authenticity Arms Race: Why AI Watermarking Fails and Regulation Must Pivot Now
The promise of Artificial Intelligence is inseparable from the fear of its misuse. As generative models become masterful at crafting realistic text, images, and video, the urgent question becomes: How do we tell what’s real from what’s fake?
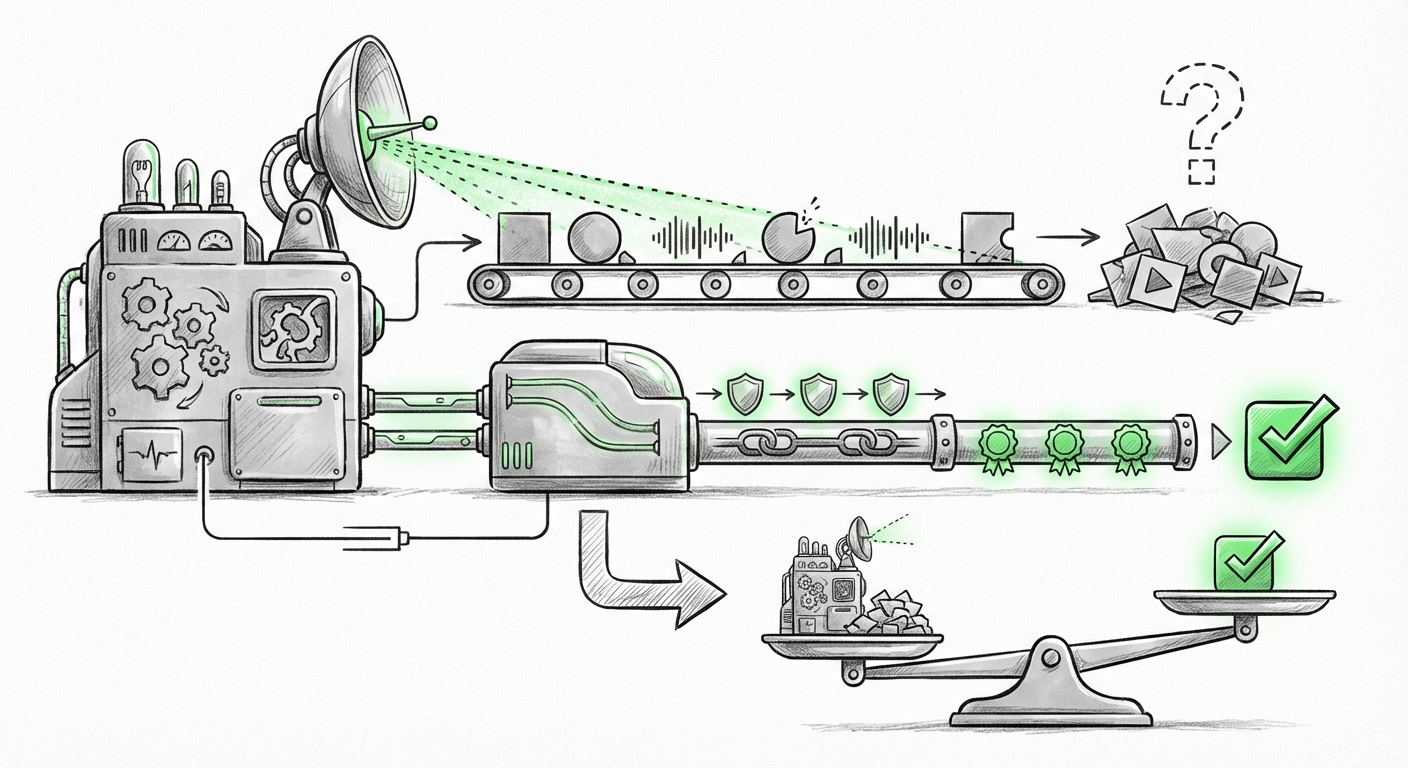
A recent, sobering technical report from Microsoft throws cold water on our best intentions. Their research systematically evaluated current methods for distinguishing authentic media from AI-generated content. The findings are stark: no single detection method works reliably on its own, and even combining multiple techniques still leaves significant gaps. This technical reality creates a massive, immediate friction point with global policy: laws are being written under the assumption that reliable authentication is possible.
As an AI technology analyst, I see this not just as a technical hiccup, but as a fundamental crisis of digital trust. If the tools meant to secure our information ecosystem are fundamentally flawed, the regulatory frameworks built upon them risk collapse, leading either to ineffective legislation or, worse, a dangerous false sense of security.
The Cracks in the Foundation: Why Detection Doesn't Scale
When we talk about "AI media authentication," we are usually referring to two main approaches: detection and watermarking/provenance.
1. The Flaw in Detection
Detection involves training a separate AI model to spot the subtle statistical artifacts left behind by generative models. Think of it like a fingerprint. The problem, as Microsoft’s research confirms, is that this is an *arms race*. As soon as a detector becomes public, bad actors can feed it into their own generative models—a process called adversarial training—to teach the generator how to specifically avoid those tell-tale signs.
For a technical audience, this is predictable: AI is designed to optimize for quality, not detection resistance. For a general audience, imagine the world's best lock pick (the detector) being handed to the world’s best safe-cracker (the generator). The safe will inevitably be compromised.
2. The Weakness of Inaudible Watermarks
The second approach involves embedding invisible signals, or "watermarks," directly into the media at the moment of creation. While useful, these too face hurdles. They can be accidentally lost through minor editing, compression, cropping, or—most critically—malicious removal using other AI tools designed specifically to scrub these signals.
Our corroborating research into adversarial attacks on AI media detection models (Query 2) repeatedly confirms this: robust detection is a moving target. If Microsoft, a leading builder of these models, admits fallibility, we must accept that post-generation clean-up is insufficient.
Policy Outpacing Reality: The Regulatory Risk
The speed of AI development has forced governments worldwide to rush legislation to maintain public safety and electoral integrity. The EU AI Act is a prime example, imposing transparency mandates that rely heavily on effective, reliable identification of synthetic content.
When we look at how the EU AI Act digital provenance requirements (Query 3) map against current technical capabilities, a gulf appears. Regulators demand assurances that systems can identify deepfakes, yet the best labs in the world cannot offer a 100% guarantee. This creates a dangerous situation:
- False Security for Consumers: Users might trust content simply because it lacks a visible warning, believing the systems have done their job.
- Unenforceable Compliance: Companies attempting to comply face impossible technical standards, leading to either non-compliance or gaming the system through superficial measures.
For businesses, this means current compliance strategies relying heavily on off-the-shelf detection tools are inherently fragile. If a high-stakes deepfake is created that bypasses a system deemed "compliant," the liability risks are immense.
The Necessary Pivot: From Detection to Digital Provenance
If detecting the fake is futile, the only viable path forward is to focus relentlessly on verifying the authentic. This shifts the paradigm from *detecting what is false* to *proving what is true*. This is where Provenance Tracking becomes the undisputed future.
The Rise of C2PA
The industry’s leading response to this challenge is the Coalition for Content Provenance and Authenticity (C2PA). This industry consortium (involving giants like Adobe, Microsoft, and others) is working to establish open standards for attaching tamper-evident metadata to content right at the moment of creation. Think of it like a digital birth certificate attached to a photo or video file.
However, as explorations into "C2PA" standards roadmap challenges (Query 1) reveal, technological standardization is only half the battle. The other half is adoption. Will all camera manufacturers, social media platforms, and AI developers universally adopt and enforce these standards? If the ecosystem remains fragmented, provenance only works within walled gardens.
Blockchain as the Immutable Ledger
Given the need for an unchangeable record, decentralized technologies are gaining traction. Research into using Blockchain for media provenance in generative AI (Query 4) suggests that immutable ledgers could store cryptographic hashes of media files. If a file’s hash matches a record created by a verified source (like a trusted news agency or an individual’s authenticated camera), it’s deemed trustworthy.
This decentralization offers resilience against single points of failure—no single company can unilaterally delete the history of a piece of media.
What This Means for the Future of AI and Society
The failure of current authentication methods forces a radical re-evaluation of digital interaction. We are moving out of the era of blind trust and into the era of required verification.
For Businesses: Rethinking Trust Architecture
Businesses must stop treating AI detection as a necessary compliance checkbox. Instead, they must proactively engineer systems around verified origin:
- Shift Left: Integrate provenance tracking (like C2PA) into all outgoing communication channels. If you generate internal training materials or marketing assets with AI, ensure they are clearly labeled and cryptographically sealed as synthetic upon export.
- Internal Verification Tools: Focus security budgets on tools that verify *incoming* content against known provenance standards, rather than trying to police all user-generated content based on unreliable detection algorithms.
- Legal Preparedness: Understand that relying on generic, easily bypassed detection software may not constitute "due diligence" under new liability laws. The standard will shift to "Did you implement the best available provenance tracking?"
For Society: The Return of Media Literacy
Technological fixes alone cannot solve a societal problem. If synthetic content becomes indistinguishable from reality without perfect metadata, the onus shifts back to the consumer. We must foster radical media literacy:
- Assume Manipulation: Users must adopt a default stance of skepticism toward sensational or emotionally charged media, especially from unverified sources.
- Source Verification Over Content Analysis: The focus must change from "Does this look real?" to "Who created this, and can their identity be verified?"
- Embrace Transparency Mandates: Support regulations that force platforms to prominently display provenance data (or lack thereof) for all media shared on their sites.
Actionable Insights for Navigating the Authenticity Gap
The next 12-18 months will define how we manage synthetic media. Here are immediate steps for technology leaders and policymakers:
For Technologists and Developers:
- Prioritize Provenance Integration: Immediately begin testing and integrating C2PA standards into all media pipelines. This is the industry’s most mature standard for origin verification.
- Document Limitations Clearly: If your organization deploys detection tools, you must explicitly document their current verified accuracy rate against known adversarial techniques. Transparency about failure points is crucial for legal defense.
- Explore Decentralized Tracing: Pilot blockchain or distributed ledger technologies to create an immutable chain of custody for high-value or sensitive media assets.
For Policy Makers:
- Differentiate Liability by Method: Regulation must evolve to distinguish between companies that simply use unreliable detection software and those that actively refuse to adopt emerging provenance standards. Liability should attach more heavily to the latter.
- Incentivize Hardware Provenance: Encourage or mandate that new cameras and recording devices embed cryptographic signing capabilities at the hardware level, making authenticity verifiable at the source, not just in the software layer.
- Fund Public Education: Regulatory frameworks must be paired with massive, sustained public investment in media literacy campaigns, teaching citizens how to read and demand digital provenance tags.
Microsoft’s research is not a declaration of defeat; it is a crucial diagnostic report. It confirms that the war on deepfakes will not be won by building a better fence around the synthesized garden. Instead, we must build a verifiable road leading back to the original seed.