The Diffusion Revolution: How Parallel Processing is Shattering LLM Latency Barriers
For years, the engine driving Large Language Models (LLMs) like GPT and Llama has been based on a simple, yet inherently slow, principle: autoregression. Think of it like writing a sentence word by word. You must finish the first word before you can even start deciding on the second, the second before the third, and so on. This sequential process has been the fundamental bottleneck limiting how fast and affordably we can deploy sophisticated AI.
Now, a breakthrough from Inception, with their launch of Mercury 2, suggests we are witnessing a genuine paradigm shift. Mercury 2 is heralded as the first diffusion-based language reasoning model. This isn't just a minor update; it’s a fundamental architectural change that promises to redefine the economics and capability ceiling of generative AI.
Understanding the Leap: From Sequential to Parallel Thinking
To grasp the magnitude of Mercury 2’s impact, we must first simplify the difference between the old and new methods.
The Old Way: Autoregression (One Word at a Time)
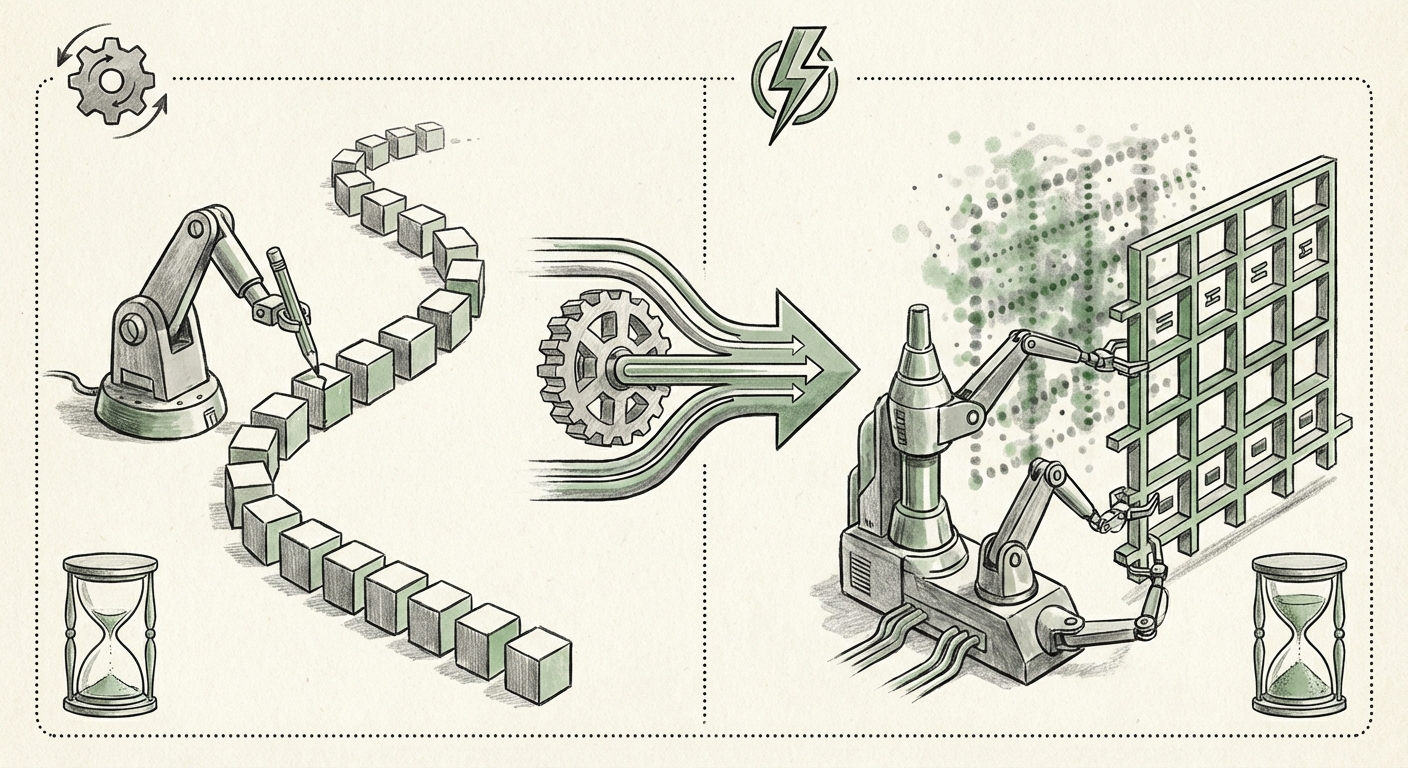
In traditional LLMs, the model predicts the next token (word or part of a word) based on all the preceding tokens. This is very good for coherence but inherently serial. If a passage is 100 words long, the model must perform 100 distinct, sequential calculation steps. This is slow, demanding high computational power (and thus, high cost) every time a response is generated.
The New Way: Diffusion (Refining the Whole Picture)
Diffusion models are the technology that powers incredible image generators like DALL-E and Midjourney. In image generation, the model starts with pure visual noise and gradually refines that noise into a coherent picture over many iterative steps. Mercury 2 applies this powerful concept to language.
Instead of generating text word by word, Mercury 2 appears to refine entire passages in parallel. It likely starts with a noisy or incomplete representation of the desired output and, in a few, highly optimized steps, denoises that entire block of text into its final, reasoned form. The result, as claimed, is a model that is more than five times faster than its conventional counterparts during inference (the process of generating a response).
This shift from sequential processing to parallel refinement is analogous to moving from sending data via a single slow mail truck to sending the entire package via a massive, parallelized fiber optic network.
The Theoretical Underpinnings and Academic Context
This move is not without precedent in research, though its successful commercial deployment marks the real breakthrough. Researchers have long explored applying diffusion techniques, initially developed for continuous data like images and audio, to the discrete world of language tokens.
A key challenge, often explored in academic literature concerning Diffusion models for text generation vs autoregressive LLMs, is handling the discrete nature of language. Pixels can smoothly transition between colors; words cannot smoothly transition between one another. Researchers have had to develop sophisticated methods to inject and remove "noise" from token embeddings in a way that results in coherent, meaningful language upon final denoising.
The successful implementation in Mercury 2 suggests Inception has cracked the code on making this process efficient enough for real-world speeds. This validates years of foundational NLP research indicating that parallel generation, if trainable, offers superior efficiency over the mandatory step-by-step nature of transformers trained only autoregressively.
The Speed War: Positioning Mercury 2 in the Inference Landscape
Speed is the new frontier in AI deployment. As models grow larger (trillions of parameters), the cost and time required to get a simple answer become prohibitive for many use cases. Mercury 2 enters a crowded field of optimization techniques.
Benchmarking Against Competing Speed Hacks
To maintain its competitive edge, Mercury 2 must be viewed against current acceleration methods explored in the Fast inference LLM architectures comparison 2024 space. Techniques like speculative decoding—where a small, fast model guesses the next few tokens, and the large model verifies them simultaneously—have offered impressive speedups, often in the 2x to 3x range.
If Mercury 2 genuinely achieves a 5x improvement through its core architecture rather than supplementary decoding tricks, it moves beyond optimization and into fundamental redesign. This places it significantly ahead of competitors relying on iterative improvements to the sequential transformer design.
For businesses tracking AI infrastructure, this 5x gain translates directly into massive cost savings. Running inference on a major cloud GPU cluster is expensive; cutting the required time by 80% means you can handle five times the query volume for the same hardware cost, fundamentally lowering the barrier to entry for high-volume AI services.
Practical Implications: Unlocking Real-Time Intelligence
The most exciting aspect of Mercury 2's performance is the door it opens for new categories of applications, moving AI from a reactive tool to a truly interactive partner. We move beyond the latency limitations discussed in research on the impact of latency on real-time AI applications.
1. True Conversational Depth and Interactivity
Current chatbots often feel disconnected because the pause between your prompt and their response is noticeable. In complex, multi-turn conversations (like technical troubleshooting or therapy simulations), this delay breaks immersion. With near-instantaneous reasoning, LLMs can keep pace with natural human speech cadence, enabling sophisticated, uninterrupted dialogue.
2. Advanced Simulation and Gaming
Imagine Non-Player Characters (NPCs) in video games that don't rely on canned responses. Mercury 2’s speed allows for complex reasoning about game states, player actions, and environment shifts to be computed in real-time, delivering unique, reasoned dialogue and action planning instantly. Similarly, complex physics or social simulations can run faster, leading to richer virtual worlds.
3. High-Frequency Enterprise Reasoning
In finance or legal tech, the ability to rapidly synthesize thousands of documents for an instantaneous summary or risk assessment becomes viable. For instance, analyzing every new regulatory filing across a dozen jurisdictions within seconds requires the speed that diffusion models promise. This shifts the value proposition from "AI can analyze this complex data" to "AI can analyze this complex data faster than a human can read the headline."
The Engineering Hurdle: Training Complexity
While inference looks phenomenal, a key question remains concerning the challenges in training large diffusion language models. Training diffusion models is notoriously demanding. They must learn how to perfectly reverse the noise process across potentially hundreds of steps.
For Inception, proving Mercury 2’s viability means they have likely solved significant engineering challenges related to:
- Discrete Optimization: Developing stable loss functions that guide the noise removal process toward grammatical, coherent language rather than meaningless text clusters.
- Scalability of Iterations: Ensuring that the parallel denoising process can scale effectively to models with billions or trillions of parameters without requiring exponentially more GPU hours than traditional methods.
The complexity of this training phase acts as a high moat. Competitors must not only catch up on the final inference speed but must also master the unique, resource-intensive training pipeline required for diffusion-based reasoning.
Future Implications: The End of the Sequential Era?
The emergence of Mercury 2 signals that the architectural dominance of the autoregressive Transformer might finally be facing a serious, viable challenger. If diffusion models prove superior in both reasoning quality (a metric yet to be fully demonstrated) and speed, the AI landscape will pivot rapidly.
The future points toward an AI ecosystem where latency is essentially eliminated as a primary concern for text generation. This democratizes access to sophisticated reasoning, making high-power AI integration simpler and cheaper across all industries, from small startups leveraging APIs to massive corporations deploying models internally.
We must watch closely for independent verification of the 5x speed claim and, crucially, the reasoning quality metrics. If speed and quality hold up, the next few years will see AI applications that currently feel futuristic become the standard expectation.
Actionable Insights for Technology Leaders
- Evaluate Inference Strategy Now: For any business heavily reliant on LLM APIs or self-hosted models, start modeling the cost savings associated with a potential 5x inference speed boost.
- Prioritize Real-Time Use Cases: Revisit product roadmaps. Features previously deemed impossible due to latency (e.g., live, intelligent coding assistance or real-time foreign language translation during calls) should now be prioritized.
- Monitor Architectural Shift: Investors and engineers should closely follow whether diffusion becomes the preferred architecture for new foundational models or if it merges with existing transformer structures (e.g., a hybrid speculative diffusion model).