The AI Microservices Revolution: How MCP Architecture and Function Calling Redefine LLM Workflows
The Monolith vs. The Modular Future: Understanding the MCP Shift
For the last few years, the conversation around Artificial Intelligence has been dominated by the sheer size of foundation models—the bigger the LLM, the smarter it seemed. While these massive models (the "monoliths") are powerful generalists, they are often slow, expensive to run for niche tasks, and lack deep expertise in highly specific domains like thermal image classification or esoteric database querying.
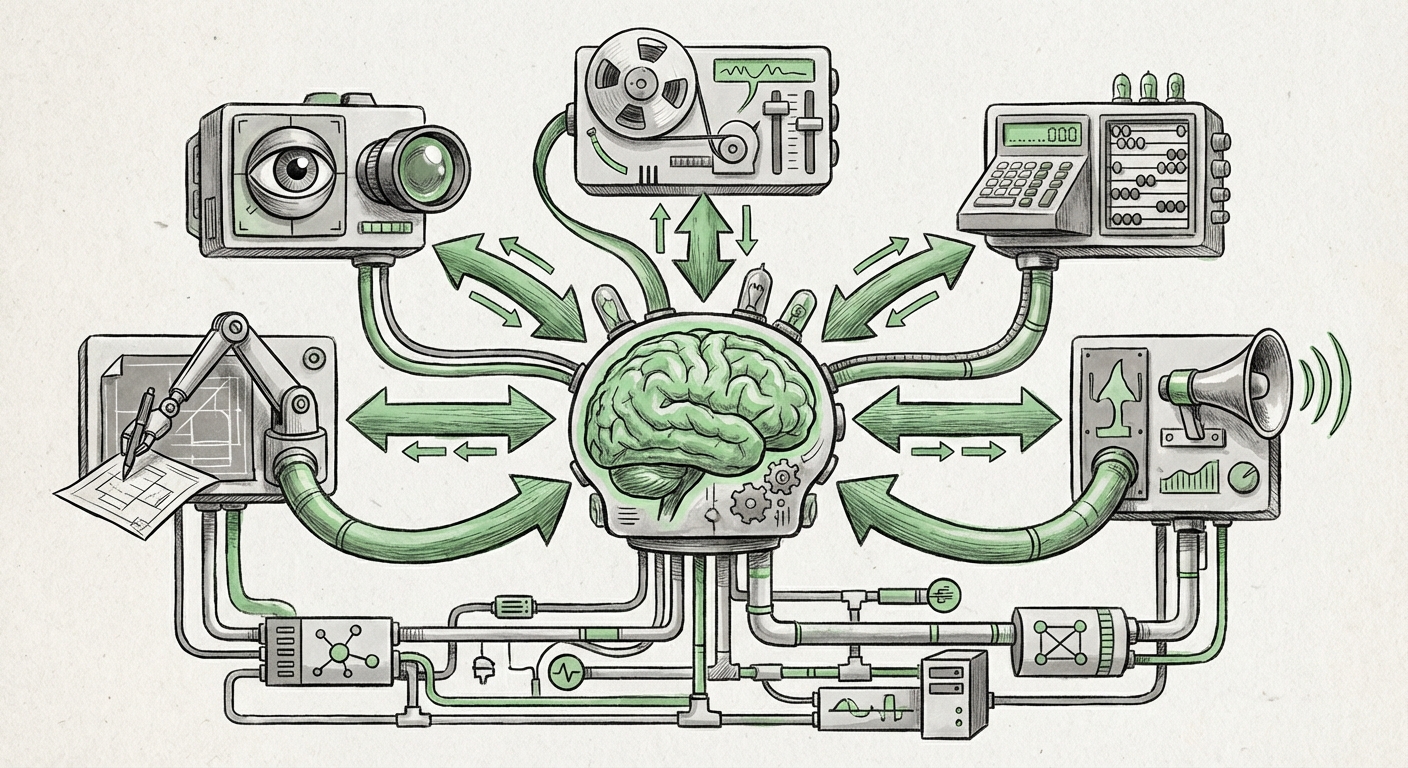
A significant, quiet revolution is now underway, shifting the paradigm toward **modularization**. This emerging pattern is exemplified by the concept of the Model-Centric Platform (MCP) architecture. Imagine replacing one gigantic Swiss Army knife with an entire specialized toolbox, where a central AI brain decides exactly which tool to pull out for the job.
The core idea, as detailed in recent technical guides, is to deploy specialized, highly optimized models as individual, accessible API endpoints—the MCPs. Instead of asking the main LLM to try and draw a perfect diagram (a task it might fail at), you ask the LLM to call a specific "Diagramming MCP" endpoint. This marks a fundamental change in how we build and deploy AI systems.
What is an MCP, and Why Does it Matter?
A Model-Centric Platform is essentially a dedicated, production-ready environment for a specific AI model or suite of models. It's not just a Jupyter notebook running code; it's a scalable, secured service built for high availability. The importance lies in specialization and efficiency. A computer vision model trained only on medical scans will almost always outperform a generalist model on that specific task, and it will do so much faster and cheaper.
This specialization addresses the "Last Mile Problem" in AI—getting accurate, real-world results for niche business needs. By externalizing these tasks to specialized MCPs, the main LLM remains focused on its strengths: reasoning, summarization, and complex instruction following.
The Glue: LLMs as Orchestrators via Function Calling
How does the generalist LLM know when and how to call these specialized MCPs? The answer lies in a powerful new capability integrated into nearly all modern LLM APIs: Function Calling (also known as Tool Use).
Think of function calling as giving the LLM a structured instruction manual for the outside world. When a user asks a question, the LLM doesn't just generate text; it first scans its "manual" (the list of available tools/MCPs). If the user asks, "Analyze the sentiment of this customer review image," the LLM recognizes that its internal text processing isn't enough. It sees it has a tool defined as `analyze_image_sentiment(image_data)`. The LLM then outputs a structured command—not an answer—requesting the system execute that function.
This reliance on function calling confirms the viability of the MCP pattern. As evidenced by ongoing research into best practices for tool implementation, this mechanism is maturing rapidly, handling schema definition and error correction better than ever. [Corroborated by the general trend in Function Calling Best Practices research.]
The Agent Ecosystem: Frameworks Building the Connective Tissue
The move to dozens or even hundreds of interconnected MCPs creates an immediate need for robust management software. This is where AI agent frameworks become essential. These frameworks (like those provided by LlamaIndex or LangChain) act as the high-level operating system for the LLM agent. They are responsible for:
- Keeping track of which MCPs are available.
- Structuring the complex chain of calls needed to solve a single large problem (e.g., "Find the data, process it with Model A, visualize it with Model B, and then summarize the result").
- Handling failures when an MCP endpoint is down or returns an unexpected result.
The successful integration of external functions into these popular frameworks demonstrates that the industry has already accepted that the LLM's role is coordination, not singular execution. [Confirmed by the ongoing development and documentation surrounding frameworks like LlamaIndex for tool integration: LlamaIndex Tool Usage Guide.]
Infrastructure Implications: A Mandate for the Ops Team
This shift is not just a software architecture change; it is a massive mandate for IT and Infrastructure (Infra) teams. The focus moves from optimizing a single, massive model deployment to managing a distributed microservices architecture for AI. This necessitates a new playbook.
From Model Ops to Platform Ops
In the MCP world, the "Model-Centric Platform" demands that the infrastructure be treated as a first-class citizen. Deploying these specialized services requires robust tooling for:
- Scalability and Cost Management: Different MCPs will have wildly different loads. A document parsing MCP might see massive spikes during month-end, while a real-time anomaly detection MCP runs continuously. Infra teams must master auto-scaling and cost allocation across dozens of endpoints.
- Latency Optimization: Function calling introduces network latency. For an LLM orchestration to feel seamless, the underlying API calls to the MCPs must be lightning fast. This pushes model serving closer to the edge and demands tight control over deployment environments.
- Observability: When a final answer is wrong, infra teams need tools to trace exactly which MCP was called, what data it received, and what response it gave back to the LLM orchestrator. This requires deep, distributed tracing across the AI pipeline.
This operational complexity is why guides specifically targeting infrastructure teams on MCP architecture are now appearing. They validate that the barrier to entry is shifting from model training talent to robust platform engineering talent. [Corroborated by infrastructure best practices discussions like securing model endpoints on major clouds: Securing Model Endpoints in Amazon SageMaker.]
The Security Surface Area Expansion
Every time an LLM calls an external API endpoint, the security risk surface area expands. For enterprises dealing with sensitive data, this is the most critical concern. If the primary LLM is compromised, can an attacker use function calling to execute malicious code or exfiltrate data via a specialized MCP?
The MCP architecture forces organizations to adopt a Zero Trust model for AI. Each deployed model service—even if internal—must be treated as a separate entity requiring strict authentication, authorization, and input/output validation. This means deploying models not just on dedicated GPU clusters, but behind secure API gateways.
Future Implications: What This Means for Business and Society
The shift toward modular, function-calling-driven AI is set to unlock significant new levels of capability and integration across nearly every industry.
1. Hyper-Personalization and Precision
Businesses will no longer settle for "good enough" general AI. They will build or subscribe to the exact models needed for their competitive advantage. A financial firm might deploy an MCP trained only on global regulatory compliance documents, instantly accessible via their customer-facing LLM chatbot. This level of domain precision was previously impossible without retraining the entire foundation model.
2. Democratization of AI Contribution
If the barrier to entry for deploying a specialized model is reduced to containerizing it and exposing a clear API, we will see an explosion of specialized AI contributors. Small companies or academic groups can build world-class models for niche tasks (e.g., identifying rare bird calls or specific geological features) and monetize them simply by making them callable tools for the broader LLM ecosystem.
3. True AI Autonomy and Agents
The ultimate realization of this architecture is the autonomous AI agent capable of planning and executing multi-step tasks without human intervention. If an agent can reliably identify when to use its internal knowledge, retrieve documents (RAG), analyze an image (Vision MCP), and then interface with a CRM system (Action MCP), we move from smart assistants to truly intelligent operational partners.
However, this autonomy comes with complexity. As we explore the trend toward specialized models, it becomes clear that the infrastructure supporting these specialized components must mature rapidly. The cost-efficiency gained by using smaller models must not be lost to overly complex orchestration layers or excessive network overhead. [This tension between specialization and orchestration complexity is a key theme in infrastructure discussions about specialized foundation models.]
4. Evolution of Skills and Roles
For the workforce, the implications are clear:
- Prompt Engineering evolves into Tool Design and Schema Management. Success will hinge on defining the contracts between the LLM and the specialized tools clearly and robustly.
- Infrastructure Engineering gains paramount importance. The reliability and security of the entire AI application depend on the robust deployment and monitoring of these interconnected microservices.
- Data Science shifts focus from training massive generalized models to the continuous improvement and rapid deployment of specific, high-accuracy service models.
Actionable Insights for Technology Leaders
To prepare for the modular future dictated by MCPs and function calling, infrastructure and technology leaders must take immediate steps:
- Audit Existing Workloads for Modularity: Identify which tasks your current large LLM is performing poorly or expensively. Can these be spun out into a dedicated, small model service? Start prototyping these as internal "tools."
- Invest in Observability Platforms: Ensure your monitoring stack can trace calls across service boundaries. You need unified logging for the orchestrator LLM *and* every MCP it calls. If you can’t see it, you can’t secure or optimize it.
- Prioritize Secure API Gateways: Treat every deployed MCP endpoint as a critical, public-facing (even if internally facing) API. Implement strong authentication, rate limiting, and input sanitization to mitigate risks associated with unrestricted function execution.
- Embrace Agent Frameworks: Do not build custom orchestration logic from scratch. Standardize on mature frameworks that abstract away the complexity of managing tool execution, allowing your teams to focus on the intelligence layer, not the network layer.
The era of the monolithic AI model performing every function inadequately is fading. The 2026 architecture is modular, specialized, and interconnected. By embracing the Model-Centric Platform strategy, orchestrated through the precise delegation of LLM function calling, organizations can transition from using AI as a novelty to embedding it as a deeply integrated, specialized, and performant engine for business operation.