The Inference Revolution: Why Language Processing Units (LPUs) and Modular AI Define the Next Hardware Era
For the past decade, the story of Artificial Intelligence advancement has been inextricably linked to one piece of hardware: the Graphics Processing Unit (GPU). GPUs were the foundational workhorses that allowed us to train massive models like GPT-4 and Claude. However, as these Large Language Models (LLMs) move out of the research lab and into everyday commercial applications—a process known as inference—the rules of the game are fundamentally changing. We are witnessing a critical inflection point where the focus shifts from raw training power to speed, cost, and specialized deployment. The emergence of concepts like the Language Processing Unit (LPU) signals that the age of the specialized AI accelerator is here.
The Inference Bottleneck: Why the GPU Isn't Always the Answer
Training a state-of-the-art LLM requires astronomical amounts of compute, which GPUs handle exceptionally well. But running that model after it’s trained—inference—is a different beast altogether. Inference demands low latency (how fast you get an answer back) and high throughput (how many answers you can give simultaneously) at the lowest possible operating cost.
This disparity has created what many in the industry call the "Inference Tax." It’s expensive to run these giants 24/7. This pressure has led engineers and infrastructure managers to aggressively seek alternatives. If you search the industry landscape, you will find evidence that the reliance on standard GPUs for deployment is wavering:
- Cost and Efficiency: General-purpose hardware is inefficient when the task is highly repetitive, like serving sequential LLM tokens. Specialized chips, often called Application-Specific Integrated Circuits (ASICs), are designed from the ground up to execute transformer architecture math with fewer transistors and less energy. Research into "Custom AI Accelerators vs GPUs for LLM Inference" consistently shows that purpose-built silicon can offer significantly better performance per watt and lower operational expenditure (OpEx) for serving tasks.
- Latency Demands: For consumer-facing applications—like real-time coding assistants or customer service bots—a delay of even a few hundred milliseconds is unacceptable. While GPUs can be fast, purpose-built accelerators prioritize a streamlined data path to minimize that critical latency.
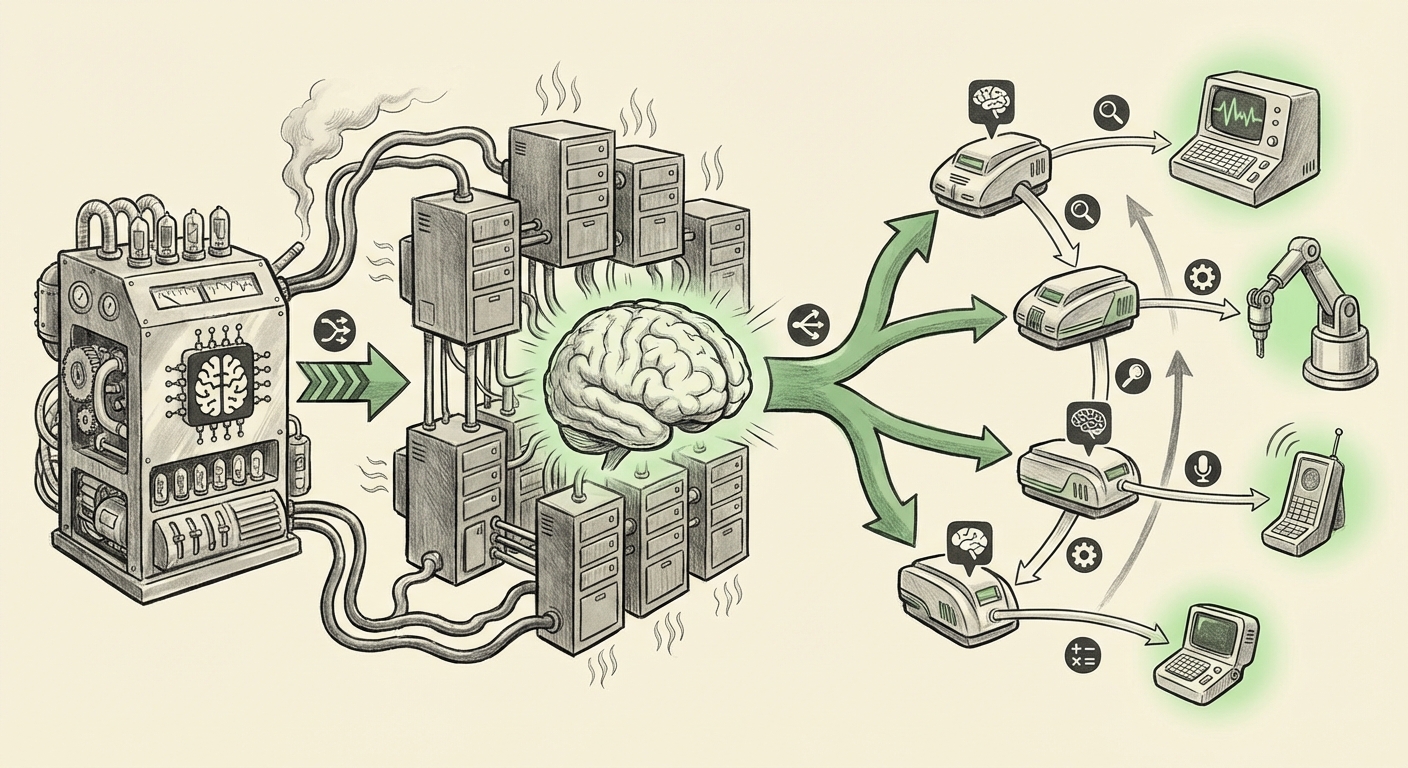
The LPU, as introduced by platforms like Clarifai, fits neatly into this narrative. It proposes a dedicated hardware layer optimized specifically for the language-centric computations of LLMs, positioning it as the superior choice for running these models once they are finalized.
The Economic Imperative: Making LLMs Affordable for Everyone
For AI to move beyond being a tech novelty and become foundational to every business process, it must become cheaper. This is the second major trend corroborating the need for LPUs: the drive for "Cost optimization LLM deployment inference."
Imagine a large enterprise needing to process millions of customer service inquiries daily using an LLM. If every query requires leasing expensive, top-tier GPU time, the business model breaks down rapidly. Analysts focusing on the Total Cost of Ownership (TCO) for deploying proprietary models highlight that while training costs get the media attention, inference costs consume the vast majority of the budget over a model's lifespan.
Specialized inference hardware addresses this economic imperative in several ways:
- Higher Density Serving: LPUs or similar inference chips can pack more concurrent user sessions onto fewer physical units, driving down the per-user cost.
- Energy Savings: Lower power consumption translates directly into lower cloud bills or reduced cooling infrastructure needs in private data centers.
- Democratization: By lowering the cost floor, smaller companies and non-tech industries can afford to embed sophisticated AI tools without massive upfront capital expenditure.
This intense focus on making deployment economically viable is the engine pushing hardware innovators to move past the general-purpose standard.
The Software Shift: Modular AI and the Rise of Function Calling
Hardware optimization is only half the story. The way we *use* LLMs is evolving just as rapidly. We are moving away from monolithic models that try to do everything, toward systems where the core LLM acts as a highly intelligent conductor orchestrating specialized tools.
This is where the concept of Function Calling (also known as Tool Use) becomes crucial. Function calling is a software paradigm that allows the LLM, after receiving a user prompt (e.g., "What's the weather in Paris, and please book me a flight there for tomorrow?"), to realize it needs external help. It doesn't calculate the flight price itself; instead, it generates a structured request—a function call—to an external API.
The LPU as a Specialized Tool
If the LLM decides it needs real-time data, complex calculation, or perhaps a very fast response for a simple task, it calls a dedicated endpoint. This is precisely where the LPU steps in. The system architecture envisions:
Core LLM (Orchestrator) $\rightarrow$ Function Call $\rightarrow$ LPU-Powered API Endpoint (Specialized Executor) $\rightarrow$ Result Returned to LLM.
This modular approach—contextualized by deep dives into "The Impact of Function Calling on AI Architecture"—provides three major advantages:
- Precision: The LLM delegates specific, predictable tasks to hardware explicitly optimized for them.
- Efficiency: You don't need to run the multi-billion-parameter model for every tiny calculation; you only run the expensive LLM for the reasoning part.
- Latency Control: The LPU can provide answers to its delegated tasks almost instantly, keeping the overall agentic workflow snappy.
The ability to easily deploy these specialized execution engines—like deploying an LPU server as a public API endpoint—is the key enabler for this entire agentic revolution. It decouples high-level reasoning from high-speed execution.
What This Means for the Future of AI: Implications for Business and Society
The convergence of specialized hardware (LPUs) and modular software (Function Calling) signals a maturation of the AI industry. We are entering the "Inference Economy."
For Businesses and Developers (The Actionable Insights)
The takeaway for CTOs and ML Engineers is clear: **Optimize for Serving, Not Just Training.**
- Rethink Your Stack: If your primary interaction with models is serving users (APIs, chat interfaces, internal tools), start auditing your current reliance on GPUs for inference. Look into inference-optimized solutions, whether they are proprietary ASICs, open-source optimized serving frameworks, or new hardware platforms like LPUs.
- Embrace Modularity: Begin restructuring your application logic around function calling or tool use. Design your application so that the LLM is an orchestrator. This allows you to plug in best-of-breed tools—whether it's a proprietary LLM, a specialized LPU microservice, or a traditional database query—without re-training the core reasoning engine.
- Cost Governance: Future cloud governance must include granular tracking of inference costs per feature, not just per GPU hour. Understanding the cost efficiency of specialized hardware will become a primary competitive advantage.
Broader Societal Implications
On a societal level, this shift promises more accessible and ubiquitous AI.
When AI services become radically cheaper to run, they become available in more places. We can expect AI to move off centralized, multi-billion-dollar data centers and into smaller, regional cloud instances or even on-premise environments where data privacy is paramount. This drive toward efficiency is democratizing access, moving AI from a luxury good reserved for the tech giants to a standardized utility available to all.
The Road Ahead: The Era of Heterogeneous Compute
The future of AI computing will not be dominated by a single chip; it will be defined by heterogeneous compute. This means using the right tool for the right job:
We will likely see systems built with a complex interplay of specialized hardware:
- Training GPUs: Still necessary for the massive, initial learning phase.
- LPU/Inference ASICs: Handling the high-volume, low-latency serving of language tasks.
- Vector Databases and Specialized Processors: Handling retrieval and memory lookup (RAG).
The LPU is more than just a new chip; it is a tangible representation of the industry acknowledging that the challenges of deployment are distinct from the challenges of training. By optimizing the silicon for the inference workload and pairing it with intelligent software orchestration via function calling, we are building an AI infrastructure that is not only smarter but crucially, more sustainable and economically feasible to operate at global scale.