The Inference Wars: Why Specialized AI Serving is Reshaping Generative Application Development
For the last few years, the story of Artificial Intelligence has been dominated by model creation—the massive Large Language Models (LLMs) that can write poetry, code, or pass legal exams. But as these powerful tools move from research labs into mission-critical business applications, the focus is shifting dramatically. The new bottleneck isn't *what* the AI knows, but *how fast* it can answer and *what* it can actually do.
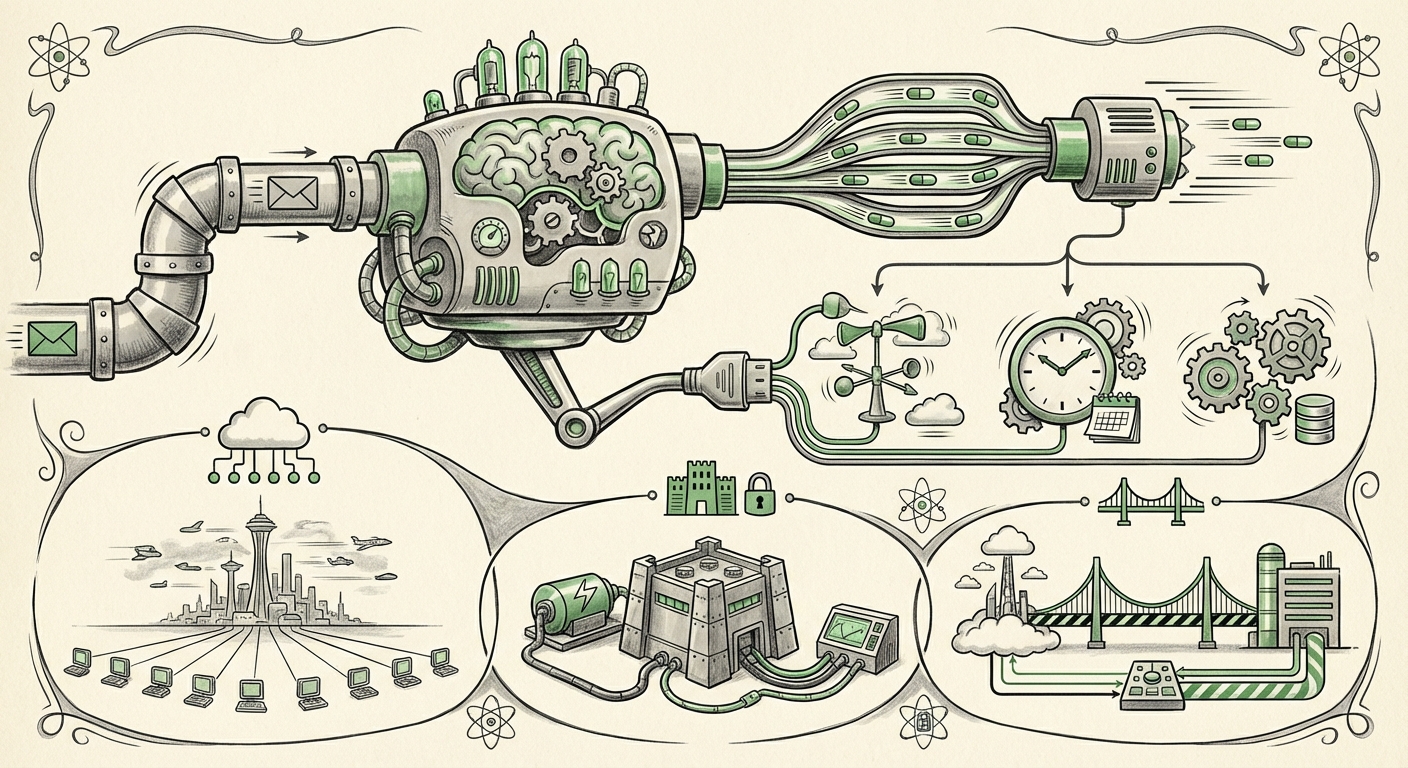
This shift has fueled what we can only call the "Inference Wars": a high-stakes battle among specialized providers to deliver the fastest, most efficient, and most integrated execution environment for these models. A recent analysis highlighting comparisons between platforms like Clarifai, Groq, Fireworks AI, and Together AI underscores a fundamental truth: the future of AI application development depends not just on better models, but on superior infrastructure.
The End of Monolithic AI Serving
Historically, if a company wanted to use an LLM, they typically went to a major cloud provider (AWS, Google Cloud, Azure) and ran the model on their standard GPUs. This model works, but it often carries high costs and noticeable delays (latency). Think of it like driving an 18-wheeler truck to pick up a single letter from the mailbox—it’s overkill and slow.
What we are now seeing is the rise of highly specialized inference providers. These companies are optimizing their entire stack—from the physical hardware to the serving software—specifically for the unique demands of LLMs. This specialization leads to three key competitive battlegrounds:
- Raw Speed (Latency): How quickly the first word appears (Time to First Token) and how fast subsequent words stream out (Tokens per Second).
- Workflow Integration: Moving beyond simple question-answering to letting the model control other software tools.
- Deployment Flexibility: Offering solutions that fit diverse enterprise needs, from public APIs to private, on-premise setups.
The Race for Sub-Millisecond Latency: The Groq Effect
If you want to understand the urgency of speed in AI inference, you must look at the emergence of hardware accelerators like Groq’s Language Processing Unit (LPU). While traditional AI runs on GPUs (Graphics Processing Units), which are fantastic for parallel computing (doing many small math problems at once), sequential tasks like generating human language benefit immensely from different architectures.
Independent benchmarks, often sought out by engineers trying to make real-time applications work, frequently demonstrate that LPUs can deliver token generation speeds multiple times faster than even the best current GPUs. For the end-user, this translates from a sluggish conversation to a real-time dialogue.
What this means for applications: For tasks like voice assistants, real-time code completion, or high-frequency trading analysis, milliseconds matter. If an AI application takes too long to respond, users abandon it. This hardware race is democratizing use cases that were previously impossible due to slow response times. It’s the difference between reading an AI-generated email five seconds later, and having the AI coach you *during* your typing.
The Pivot to Action: Function Calling and Agentic AI
The capability that truly transforms LLMs from clever toys into indispensable business assets is the ability to use external tools—a feature commonly known as Function Calling or Tool Use. As discussed in comparisons of modern platforms, providing robust function calling integration is now a core feature, not an afterthought.
Imagine asking a standard chatbot, "What is the weather?" It tells you the weather based on its training data, which might be six months old. Now, imagine asking an LLM with function calling:
- The LLM recognizes it needs current data.
- It generates a structured command (a 'function call') to an external weather API.
- It sends this command, receives the structured data back (e.g., JSON format).
- It interprets that data and replies naturally: "The weather in London is currently 15 degrees Celsius and sunny."
This capability allows the LLM to become the "brain" orchestrating complex enterprise tasks: booking flights, updating customer databases, running proprietary analytics, or generating reports based on live financial feeds. The key insight here, confirmed by industry analysis of developer priorities, is that the reliability and ease of integrating these tools are now more important to developers than simply having the largest model.
Actionable Insight for Businesses: Focus your immediate LLM investment on platforms that treat function calling not just as a feature, but as a core, reliable part of their API. If your goal is to build AI agents that interact with legacy systems, the quality of this integration dictates your success rate.
The Infrastructure Spectrum: Cloud, Edge, and Hybrid Demands
While providers like Clarifai offer public, managed servers accessible via an API (the "Public MCP servers" mentioned in initial analyses), this centralized cloud approach doesn't suit every organization. The "Inference War" is also being fought across the deployment spectrum:
1. The Cloud Specialists (Speed & Scale)
Providers like Together AI and Fireworks often specialize in offering optimized access to a wide range of open-source models at competitive prices, leveraging economies of scale and specialized hardware pooling. They are the ideal choice for startups or teams needing flexible model access without managing infrastructure.
2. The Enterprise Mandate (Data Sovereignty)
For banks, healthcare providers, or defense contractors, sending sensitive data outside their own secure network—even to a trusted vendor—can violate compliance rules or be deemed too risky. This creates massive demand for self-hosted solutions.
This is where open-source serving engines, like those often benchmarked against vLLM, become critical. They allow enterprises to take a high-performing model and run it entirely on their own servers (on-premise or in a private cloud). The value here is control over data and predictability of latency, even if initial setup is more complex.
The Future is Hybrid
The realistic future for most large organizations is a hybrid model. They might use the ultra-low-latency public APIs for customer-facing interfaces where data is generic, while using their private, self-hosted infrastructure for core, sensitive data processing. The technology trend is pushing providers to offer unified tooling that manages both environments seamlessly.
What This Fragmentation Means for AI's Future
The evolution from a single cloud infrastructure to a specialized ecosystem of inference providers has profound implications for how we build, invest in, and regulate AI.
For Developers: Tooling Over Training
The barrier to entry for building powerful AI applications is dropping rapidly. Developers no longer need massive GPU clusters to fine-tune models; they need expert knowledge in prompt engineering, system design, and, most importantly, workflow orchestration (function calling). Future success will be measured by how cleverly you connect these specialized inference endpoints together.
For Businesses: Optimization is Key
The era of simply paying a premium for access is ending. Businesses must now optimize for cost *per meaningful action* rather than just cost *per token*. Does the slightly more expensive, faster Groq service save you more in operational time than the cheaper, slightly slower managed service? Can you gain compliance by shifting 30% of your workload to an on-premise vLLM deployment?
This requires an MLOps strategy focused entirely on deployment performance metrics, not just model accuracy metrics.
For Society: Performance and Access
High-speed inference democratizes access to sophisticated AI experiences. When AI interaction feels instant, it becomes woven into the fabric of daily life—from accessibility tools that interpret complex information in real-time to industrial automation that requires immediate feedback loops.
Conversely, the complexity of the infrastructure layer—the choice between LPU, specialized GPU clusters, or open-source engines—could inadvertently create new barriers. Ensuring that these advanced, fast services remain accessible and affordable across different organizational sizes will be crucial for equitable AI progress.
Actionable Takeaways for Navigating the Inference Landscape
As an organization looking to build reliable, production-grade AI applications today, here are three immediate steps derived from these trends:
- Benchmark Latency, Not Just Cost: When evaluating inference providers (Clarifai, Fireworks, Together AI, etc.), establish a strict latency threshold for your primary user-facing tasks. If your application requires sub-second interaction, prioritize providers showcasing dedicated acceleration (like Groq’s architecture) or highly optimized open-source serving stacks (like vLLM).
- Prioritize Agentic Capabilities: Ensure the chosen platform offers mature, well-documented function calling. Test the platform’s ability to reliably interpret and execute external tools across various input types. This capability defines the operational ceiling of your AI agents.
- Map Your Deployment Strategy: Immediately categorize your data and use cases into categories: Public (latency-critical, non-sensitive), Private (high sensitivity, compliance-heavy), and Hybrid. This will guide whether you rely on managed public MCPs or invest in engineering resources for a self-hosted, hybrid solution.
The competition in AI inference is heating up, driven by the need for speed and the desire for tangible action. Infrastructure is no longer just the plumbing; it is now the differentiating feature. Those who master the intricacies of specialized serving environments will be the ones building the next generation of indispensable AI applications.