The Unified AI Era: How Google's Gemini Embedding 2 Is Rewriting the Rules of Multimodality
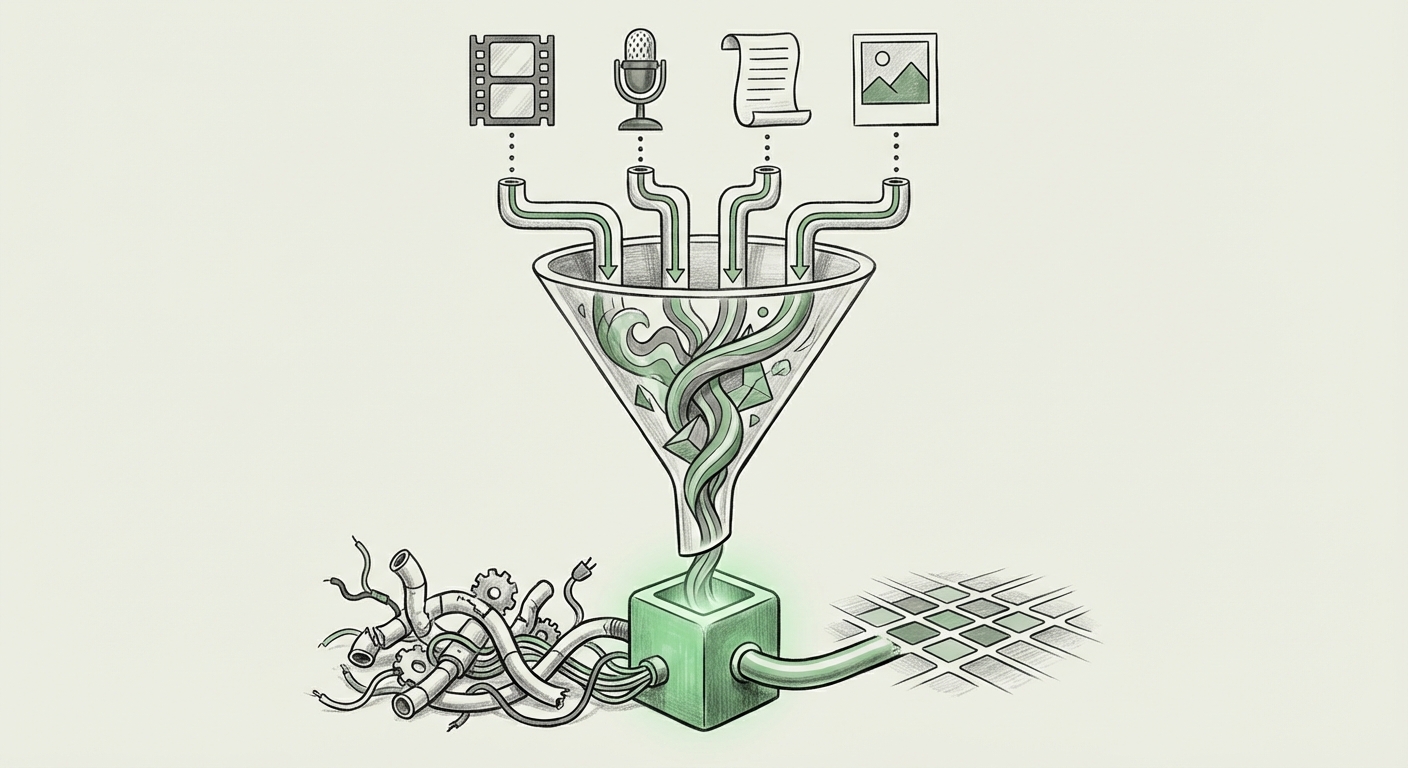
The pace of AI innovation often feels like a relentless series of incremental steps. However, every so often, a foundational architectural shift occurs that simplifies complexity and unlocks entirely new possibilities. Google’s recent announcement of Gemini Embedding 2 represents precisely such a moment. By successfully collapsing text, images, video, and audio data into a single, cohesive vector space, Google is not just improving current models; they are fundamentally changing the blueprint for future AI systems.
The Core Breakthrough: Beyond Separate Silos
To understand the significance of this unification, we must first understand the "before" state. Historically, Artificial Intelligence systems that needed to understand multiple types of data—say, processing a video that contains speech, on-screen text, and visual action—required a complex pipeline:
- A separate model analyzed the audio track (audio embedding).
- Another model processed the text captions (text embedding).
- A third model interpreted the video frames (image/video embedding).
- Finally, a complex fusion layer tried to reconcile the output of these three *separate* languages into one understandable concept.
This process is slow, prone to error (as information is lost during translation between models), and incredibly resource-intensive. It's like asking three specialists who speak different languages to simultaneously describe the same event to a fourth person, who must translate and merge their descriptions on the fly.
Gemini Embedding 2 bypasses this entirely. It creates a native multimodal space where, conceptually, the embedding for the *word* "dog," the *image* of a dog, the *sound* of a bark, and the *video clip* of a dog running all occupy points that are mathematically close to each other. They speak the same underlying language.
Corroboration and Industry Context
This move signals a clear industry direction. While specialized models like OpenAI’s CLIP (Connecting Text and Images) paved the way, the next frontier is truly holistic understanding. Reports tracking the "State of Multimodal Embeddings 2024" consistently point toward this convergence. The race is no longer just about making models bigger, but making them architecturally smarter and more integrated. For Google, embedding technology—how machines map data into understandable vectors—is the bedrock of everything from search to generative AI. A unified embedding model ensures their entire AI stack speaks one coherent language.
Implications for Retrieval-Augmented Generation (RAG) and Search
The most immediate and transformative impact will be felt in knowledge systems, particularly those leveraging Retrieval-Augmented Generation (RAG). RAG allows large language models (LLMs) to access external, real-time information, drastically reducing hallucinations and improving accuracy for enterprise applications.
The Power of True Multimodal RAG
The query, "Impact of Unified Vector Spaces on Semantic Search and RAG," highlights why this matters for businesses. Imagine an engineer needing maintenance information:
- Current System: The engineer searches for "Error code 404 on hydraulic press." The system returns PDF manuals (text) and maybe some old troubleshooting emails (text).
- Gemini Unified System: The engineer uploads a one-second video clip of the failing machinery, speaks the error code aloud, and asks, "What just happened?" The unified model simultaneously retrieves the relevant diagram from a PDF, the specific audio clip from a recorded maintenance call where the error was fixed last year, and the exact timestamp in a training video showing the repair sequence.
This is semantic search taken to its logical conclusion: retrieving *meaning* across all data formats, not just matching keywords. For industries dealing with rich media—like media archives, scientific research labs, manufacturing logs, or medical imaging—this simplification of the retrieval process is revolutionary.
The Engineering Hurdle: Complexity and Coherence
While the concept sounds simple, achieving it is a monumental feat of engineering, as highlighted by exploring the "Challenges in Training Large Multimodal Models (LMMs)."
Data modalities are fundamentally different. A video frame is a grid of pixels; audio is a time-series waveform; text is a sequence of discrete tokens. For these to share a common vector space, the training process must align their underlying semantic meaning perfectly. If the model learns that the visual representation of "sadness" in a video is far away from the textual description "unhappy," the system fails.
Google’s success suggests they have mastered the delicate art of cross-modal alignment at scale. This implies massive, high-quality, perfectly labeled multimodal datasets and highly optimized training infrastructure (likely relying heavily on TPUs). This technical barrier to entry is high, solidifying Google's current lead in this specific architectural domain.
The Race for Coherence
This engineering mastery directly influences the future viability of these systems. A unified space demands computational efficiency. If integrating four separate modalities requires four times the processing power, the practical benefits disappear. A successful unified model must be *leaner* in deployment, even if it was expensive to train. The efficiency gains realized by having one model handle everything, rather than orchestrating four separate ones, are key to rapid, scalable deployment across consumer and enterprise products.
The Competitive Landscape: Responding to Architectural Disruption
Any major move by Google immediately prompts market reactions. Analyzing the "Competitor Response to Unified Multimodal Embeddings" shows this is perceived as a direct challenge to the current leaders in foundational models.
For competitors like OpenAI, who have demonstrated incredible power with models like GPT-4o (which handles multiple modalities in real-time conversation), the focus shifts. While GPT-4o excels at real-time interaction, Gemini Embedding 2 emphasizes the *representation* layer—the foundational math that stores and compares data across media types. This suggests an industry split: one group prioritizing instantaneous multimodal conversation, and the other prioritizing robust, deeply coherent data storage and retrieval architecture.
The market now expects all major foundational model providers to offer comparable, unified embedding capabilities. This forces innovation toward reducing the "modality tax"—the computational penalty previously paid for handling diverse data types.
Future Implications: What This Means for Developers and Society
The shift to unified embeddings is more than a technical footnote; it is the foundation of the next generation of human-computer interaction.
1. Hyper-Personalized Agents
Imagine personal AI assistants that truly know your entire digital history: every photo you’ve taken, every meeting you’ve recorded, every email you’ve sent. If all this data exists in one coherent space, the agent can reason across it instantly. Asking your agent, "Show me the best vacation photos where I was wearing the blue shirt I bought last summer, set to the music we listened to during that trip," becomes trivial. The agent doesn't search photos, then search for a purchase record, then search music files separately; it finds a highly localized "cluster" in the unified vector space representing that entire memory.
2. Democratization of Data Understanding
For developers, the barrier to entry for building sophisticated multimodal apps drops significantly. Instead of requiring expertise in video codecs, audio fingerprinting, and NLP tokenization, a developer simply needs to feed the raw data into the embedding layer and retrieve vector representations. This accelerates development cycles for applications in areas like:
- Accessibility: Instantly generating accurate, context-aware video descriptions for the visually impaired.
- Security & Monitoring: Building surveillance systems that can flag an anomaly based on the *combination* of a specific sound (a breaking window) and a corresponding visual cue (a shadow moving quickly).
3. The Evolving Definition of "Data"
This technology challenges how we think about unstructured data. In the unified embedding world, data is less about its original file format (MP4, WAV, TXT) and more about its semantic fingerprint. This pushes the data management industry toward vector databases as the primary storage mechanism, rendering traditional file systems secondary for advanced analytic purposes.
Actionable Insights for Leaders
For organizations looking to capitalize on this shift, several strategic moves are critical:
- Audit Your Data Stack: Identify critical knowledge bases that currently exist in siloed formats (e.g., video archives separate from text documentation). Begin planning migration strategies to unify metadata indexing based on semantic vectors.
- Prioritize RAG Upgrades: If you are using RAG, assess how you currently handle non-textual data (if at all). The next generation of competitive advantage will come from RAG systems that can query and synthesize information across all modalities natively.
- Invest in Unified Talent: The engineers who understand how to align disparate data types in vector space are the most valuable. Foster internal skills in advanced vector database management and cross-modal training techniques.
Conclusion: A Foundation for True Context
Google’s commitment to a single vector space for text, image, video, and audio is not just an iterative improvement; it is the necessary structural prerequisite for Artificial General Intelligence (AGI) applications that interact with the world as humans do—holistically.
By erasing the mathematical boundaries between sensory inputs, Gemini Embedding 2 allows AI systems to perceive context, memory, and intent with unprecedented clarity. The future of AI architecture is unified, and the systems that adopt this coherence first will undoubtedly define the next decade of technological capability. The fragmentation of data understanding is officially drawing to a close.