The Unified AI Frontier: How Single-Space Multimodal Embeddings Redefine Intelligence
The pace of innovation in Artificial Intelligence often feels like a series of incremental steps. However, every so often, a development occurs that feels less like a step and more like a tectonic shift in the underlying architecture of how intelligence is modeled. Google’s announcement regarding its native multimodal embedding model, which unifies text, images, video, and audio into a single vector space, marks precisely such a moment.
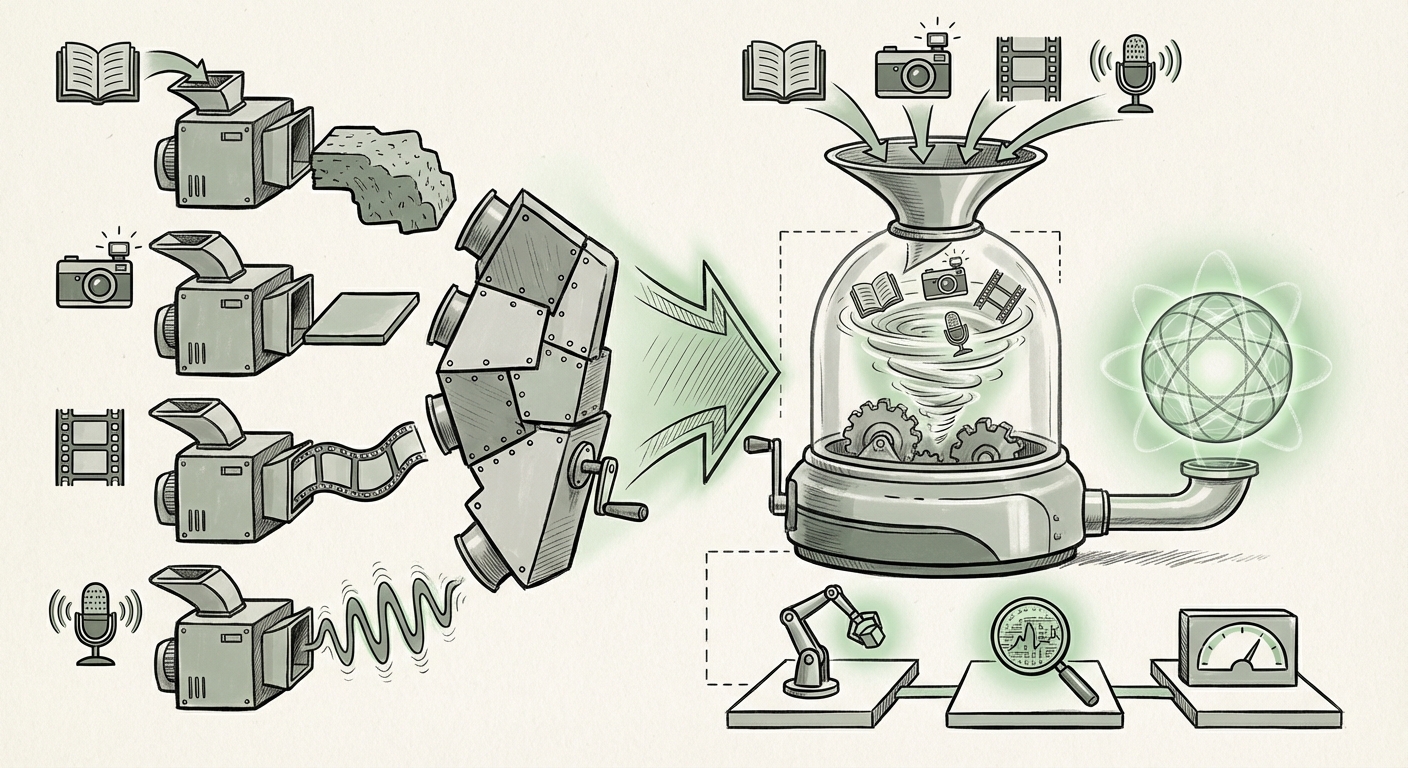
For context, an embedding is the numerical language AI uses to understand data. Previously, if an AI needed to understand a video, it often used one model to process the visual frames, another for the spoken audio track, and yet another for any accompanying text captions. These pieces were then bolted together. Now, with a unified approach—like the one demonstrated by Gemini Embedding 2—all these pieces are translated into the same mathematical neighborhood, allowing the AI to reason across them natively. This is the transition from specialized tools to a universal translator for sensory input.
The Technical Leap: Why a Single Vector Space Changes Everything
To understand the significance, we must look beyond the surface-level marketing. The core innovation lies in semantic coherence across modalities. When everything lives in the same mathematical space, the relationship between the text "a happy golden retriever running on a beach" and an actual video clip of that exact scene is represented by the distance between their respective vectors.
This unification directly addresses a long-standing problem in AI: the handoff friction between different data types. This is where the technical audience finds the greatest insight. As implied by the need to explore technical deep dives (Query 1: `"multimodal embedding space" technical implications vs unimodal`), the benefits are profound:
- Efficiency and Cost: Instead of running four separate encoder models (one for each modality) and fusing the results, a single, highly optimized encoder can generate the cross-modal representation. This reduces computational overhead and latency significantly.
- Deeper Reasoning: True understanding means knowing that the sound of waves (audio vector) correlates directly with the visual representation of the ocean (image/video vector). A unified space forces the model to align these concepts, leading to better zero-shot learning—the ability to perform a task it wasn't explicitly trained on.
- Simplified Pipelines: For engineers, the complexity of maintaining and updating separate modality pipelines evaporates. The entire data stream can be ingested and processed through one consistent API endpoint.
For readers new to the field, imagine trying to learn a foreign language by only reading the dictionary (text) versus watching films with subtitles (multimodal). The latter provides context, emotion, and visual cues that make the language stick. A unified vector space gives the AI that contextual ‘film’ experience for every piece of data it processes.
The Competitive Arena: Reshaping the Foundation Model Race
Google's announcement is not happening in a vacuum. It is a calculated response and a competitive salvo in the ongoing race for AI supremacy. The competition (Query 2: `OpenAI vs Google multimodal embeddings strategy comparison`) focuses intensely on who can build the most capable and coherent "Foundation Model"—the massive base model upon which all future applications are built.
When models like OpenAI’s GPT-4o demonstrated native multimodal understanding, the industry took notice. Google’s move with Gemini Embedding 2 solidifies the industry consensus: the future of AI is not just text-in, text-out; it is sensing the world holistically.
What This Means for Strategy
For executives and investors, the question shifts from *if* multimodal models will dominate to *who* has the superior architectural advantage. A truly unified embedding space offers a powerful moat. If your core index understands the relationship between every piece of media you possess—your company’s training videos, customer service call recordings, internal documents, and product images—in the same way, your ability to innovate on top of that data becomes exponentially faster than competitors relying on older, siloed integration methods.
This development confirms that the battleground is now the ability to ingest and process the messy, complex reality of the physical world, which is inherently multimodal.
Enterprise Reality: Infrastructure and the Vector Database Challenge
A breakthrough in modeling is only as good as the infrastructure that supports it. This is where we must ground the discussion in practical enterprise adoption (Query 3: `Vector database support for unified multimodal embeddings`). Modern AI relies heavily on vector databases to store these embeddings and perform lightning-fast similarity searches—the backbone of Retrieval-Augmented Generation (RAG) systems.
If an organization has petabytes of data encoded using older, siloed text and image embeddings, upgrading to this new unified standard requires significant effort. They must re-encode their entire data lake.
The Indexing Imperative
Vector databases must evolve to handle these new, potentially higher-dimensional, and semantically rich vectors efficiently. We are looking at a demand for:
- Re-indexing Cycles: Businesses will need to dedicate significant computational resources to re-embedding their historical data using the new unified standard to unlock its potential.
- Performance Benchmarks: The effectiveness of a unified search depends on the vector database’s recall rate. Can it accurately find a specific 5-second audio clip within an hour of meeting footage by searching a text query? New benchmarks will emerge to test this capability.
- Unified Search Interfaces: The user experience simplifies: one search bar, one set of results, whether the source is a document, a spreadsheet, or a voice memo. This drives down the barrier to entry for complex data analysis.
For IT decision-makers, this means preparing MLOps pipelines not just for model training, but for massive, ongoing data transformation and indexing projects.
The Future of Interaction: Embodied AI and System 1 Reasoning
The most exciting, forward-looking implication lies in how these unified models pave the way for true, seamless interaction between AI agents and the physical world. This is the realm of robotics and embodied AI (Query 4: `"Native multimodal models" impact on robotics and embodied AI`).
Human intelligence is fast, intuitive, and based on integrated sensory input. When a child sees a dog bark, they instantly connect the sound, the sight, and the concept of "dog." They don't process the sound in one lobe and the sight in another, waiting for the brain to translate. This is often called "System 1" thinking—fast, automatic perception.
By forcing all sensory data into one vector space, models like Gemini Embedding 2 move closer to simulating this intuitive reasoning. Consider an advanced service robot:
- Scenario: A user says, "Please clean up that spilled coffee on the counter."
- Old Method: The speech-to-text model processes the audio, the vision model identifies the liquid (if it can even distinguish coffee from water), and a reasoning layer stitches it together. Errors are common in translation.
- Unified Method: The model ingests the audio waveform, the visual scene (identifying color, viscosity, and shape of the spill), and the semantic command simultaneously. The resulting vector accurately represents the *event* of the spill, making the instruction execution faster and more robust to noise or unclear phrasing.
This capability is essential for creating reliable AI assistants that move beyond chatbots into physical tasks, from advanced medical diagnostics (integrating MRI scans, doctor's notes, and patient history) to complex manufacturing oversight.
Actionable Insights for Navigating the Unified Era
For organizations looking to capitalize on this architectural pivot, several immediate actions are warranted:
1. Audit Your Data Modalities
Stop treating audio, video, and text as separate data silos. Begin inventorying these assets and assessing the cost/benefit of running a comprehensive re-embedding project. If you are heavily invested in customer experience (CX) data, the ability to search across call transcripts, video transcripts, and chat logs seamlessly is an immediate productivity booster.
2. Prioritize Unified Search R&D
Experiment immediately with using multimodal embeddings for internal knowledge retrieval. Can a unified vector search engine find relevant engineering schematics (images/PDFs) just by querying a recorded meeting transcript (audio/text)? The first companies to master this cross-modal internal search will gain significant operational efficiency.
3. Re-evaluate Vendor Lock-In
If your current MLOps stack is deeply customized around single-modality encoders, start planning for modularity. The market is moving toward standardized, unified embedding outputs. Ensure your vector infrastructure can swap out the underlying embedding generator without dismantling your entire application layer.
Conclusion: Beyond Fusion to True Synthesis
The move to a single vector space for text, image, video, and audio is not just about adding more data types to an existing model; it signifies a commitment to creating AI that doesn't just process data, but synthesizes reality. It moves the technology from simple fusion—sticking separate pieces together—to true synthesis, where the meaning derived from the whole is greater than the sum of its sensory parts.
This trend, corroborated across the competitive landscape and driven by the demands of future applications like robotics, ensures that the next wave of AI breakthroughs will be fundamentally driven by models that see, hear, and read the world as a single, continuous stream of information. The architecture of intelligence is officially unified.